AI in 2024:
Real Talk, Industry Trends, Hot Takes, and Weird Flexes
Paco Xander Nathan
Austin Forum (2024-04-16)
https://www.austinforum.org/april-16-2024.html
Early stages of almost every civilization-changing technology shift tend to be exotic. Mathematicians arrive a few years in to restate early ad-hoc solutions in terms of algebraic objects, joint probability distributions, etc. In other words, evil mad scientists run optimizations and perform risk analysis to inform large capital investments. In the case of currently popularized notions of "AI" — i.e., large transformer models with astoundingly improved abilities for sequence-to-sequence learning, diffusion, etc. —
the underlying technology is literally based on algebraic objects and joint probability distributions, so we can expect the later-stage math to work well.
The world's top firms which dominate online marketing (Microsoft, Alphabet, Meta, Amazon, Apple, etc.) have flexed their marketing muscles to jockey for pole positions, asserting claims of dominance in AI. Notable celebrities in the AI game seized this context to grab sensationalized headlines. Such claims — coming from either end of the "AI Doomers" vs. "Accelerationists" false dichotomy — have been largely ignorant of even the most basic post-WWII lessons in Philosophy and Poli Sci. To wit, most AI experts and their headline stories could be eviscerated by a first-year Anthropology student.
In spite of those theatrics, what had been a matter circa 2022 of a "magic eight ball" controlled by cartel-ish deep pockets is rapidly giving way to open source AI models ascending the Hugging Face leaderboards. This process is quite similar to how energy grids in the US regularized during the early 20th century. With these transformations, we're beginning to see AI apps flourish in industry. Moreover, investments in advanced computing now parallel the total technology funding in Project Apollo during 1960-1973, when the US invested $25.8B for the moonshot (~$300B inflation adjusted in 2024).
In this talk we'll look into the industry AI apps gaining traction, plus a gentle intro to the advanced math and hardware trends driving cloud economics — all from jargon-free, intelligible, business-friendly perspectives. TL;DR: "Thar be windfalls."
In tech, people tend to read headlines. Perhaps they read some content “above the fold”, though not much further beyond that unless an article gets hyped. When the pundits appear to be saying much the same thing about an emerging subject, consensus gets declared. Execs commit to strategies based on the pundits. Done and done.
Then after a while you begin to hear things, contrarian notions bubbling up… Eventually the counterfactuals evolve into heresies and schisms. Headlines fade as mitigating reports from practitioners get collected. Then the industry recognizes how a new technology actually works. Some of the larger pundit-lovin’ vendors may crash spectacularly, but history progresses and we all move onward through the fog.
Pro-tip: at O’Reilly Media we used punditry-generative FUD for the “decoy” wrong answers on multiple-choice questions in our technology certification exams.
If you’re the kind of person who makes business decisions about technology based on what Gartner says, this talk may be quite illuminating. Or, you may find it utterly blasphemous. Either way, this evening should be entertaining. I’m not going to mince words.
Now, Gartner Research and their ilk — they aren’t entirely wrong. OTOH, they’re rarely correct. Gartner makes a living by misquoting actual experts en masse and tends to “say everything” to avoid accountability.
That said, Gartner is myopic. Or rather, they cause people to not be able to make sense of an eye chart, almost as an acquired syndrome.
Much of my work — with Ben Lorica and other colleagues — serves as a kind of “corporate optometry” for people working on AI use cases in industry.
To that point, this evening I’d like to talk with you candidly about a difficult but important aspect of business, which has become increasingly crucial in the context of AI circa mid-2024: What to believe. You will need to decide about that, although in this talk we can cover some primary sources, recommended learning materials, events, forums, etc., to help with those decisions.
Pro-tip: understanding who’s legit in this game, or not, may become vital to the longevity of your business venture.
We’ll also drop some practical economic theory you probably haven’t encountered before, along with an obscene amount of advanced mathematics. Just kidding, there will only be a wee bit of advanced mathematics, although it will be obscene! Plus LOADS of primary sources and recommended learning materials. Organized as a collection of interwoven vignettes, with a nod to The Gutenberg Galaxy. Here’s a small book written just for you.
For context, I lead a team focused on open source integration for ML applications in enterprise use cases. Our results have a “CADS” brand:
Here this evening, I’ll try to stay on-brand.
Pro-tip: Hugging Face provides excellent resources for learning about the current generation of AI tooling. Their content aligns closely with the four points about brand above: https://huggingface.co/learn/cookbook/
We could wrap the talk on this point, but let’s push further…
I’ve been around for ~2 billion seconds (with a nod to Mark Pesce).
Four-thirds of a billion seconds I’ve spent working in AI. Against all advice from mentors at the time, I studied AI in grad school in the mid-1980s, guided by Douglas Lenat, Richard Cottle, Bradley Efron, Alice Supton, Mark Horowitz, Brian Reid, Stuart Reges, et al. Through a CS teaching fellowship (which paid for aforementioned studies) I launched the popular Residential Computing peer-teaching program at Stanford, where live-in RCCs provided Internet/personal computing expertise in dorms, mostly on behalf of appreciative fuzzy studies majors.
I moved to Bell Labs, got to study briefly with Bjarne Stroustrup and worked on a neural network research team led by John Hopfield for a hot minute, before AT&T fell into a death-spiral of corporate reorgs. After more X.25 and X 11 R3 than one may care to recall, I moved to Austin and became software lead for an early neural network hardware accelerator project. Following this project after it spun out of Motorola, this led to becoming CTO for a publicly-traded firm on NASDAQ. Afterwards, lots of subcontracting through SAIC and cut-over to network engineering when nobody cared much about data or AI.
Eventually I became a guinea pig for a project called “AWS”, and our team fixed Hadoop to run efficiently in the cloud. Then led data teams in industry and eventually got a fun gig as open source community evangelist for Apache Spark during Databricks’ hyper-growth.
These days I lead Derwen, spend a lot of time working in España, am an open source committer, an advisor to tech start-ups, author/speaker/instructor, assist with several tech conferences, etc.
For two-thirds of a billion seconds, I lived here in Austin. My spouse grew up in Austin, our kiddos were born here. I used to run a bookstore/performance art space on The Drag called FringeWare, located next to Mojo’s Daily Grind — while writing for magazines like bOING-bOING and Mondo 2000, and producing performance art.
Many cherished memories!
x.com/matvelloso/status/1065778379612282885
I find Velloso’s cynicism to be apt, hilarious, though appallingly trite. YMMV.
A better working definition for Artificial Intelligence is one that traces lineage back to Heinz von Foerster, Margaret Mead, Gregory Bateson, et al., at the Macy conferences, mostly signified by second-order cybernetics. Namely, consider AI as a process of “mutual understanding within systems of people and machines collaborating together.” A condition where the observer becomes an essential part of the system. To wit, "cybernetics where circularity is taken seriously" — this point is subtle and crucial, and we’ll return to it later, talking generally about language and cognition. For deep-dives into background materials see:
A pull-quote from Davies:
What happened was that in trying to solve the problems of the general question of “control and communication in the animal and the machine”, people came up with ideas that were applicable to other problems. The solutions to these problems helped them design fantastic new machines, things which had actual commercial applications beyond the demonstration of simple ideas about control and representation to seminars. And within a decade or so … most of the effort had been diverted toward the new and useful technological projects of computation and telecommunications, rather than to the potentially profound but frustratingly stalled research program of cybernetics.
There’s a flip-side to these definitions of AI. On the other end of the continuum, people grow wide-eyed and nearly schizophrenic while exclaiming that they’ve achieved the invention of “consciousness” within some kind of device.
To be clear, humanity’s collective understanding about consciousness at this point is miniscule at best. It’s probably something better left to yoga instructors and B-rate film directors. If you have anyone on staff who claims to have invented consciousness…
The drill: call Security, have them walked out the door, you’ll thank me later.
Our understanding of cognition is an entirely different matter. Tracing back through the history of neural network research, the Macy conferences, second-order cybernetics, Project Cybersyn, formal definitions for cognition, etc., there’s a relatively soft-spoken but pivotal figure who emerges: Humberto Maturana, AI’s most-valuable player in the 20th century:
Frog retina neural structure, depicted by Pedro Ramon Cajal (1909)
which helped inform “perceptron” models at MIT
These definitions of cognition — thanks to Maturana’s influences, leadership, and many collaborations — provide effective foundations for AI. And for good living in general!
Pro-tip: when you talk about "AI", don't use pronouns. Instead of talking about "an AI" or "the AIs", refer to a practice instead. Simply changing your patterns of utterance will change your lines of inquiry and conceptualization.
We could wrap the talk on this point, but let’s push further…
Roll-forward to 2024. Another interesting source for the definition of AI is to study GTC keynotes by NVIDIA co-founder and CEO, Jensen Huang.
This is Jensen’s bi-annual party thrown on behalf of close friends such as Michael Dell. He’s selling. And, much like how in 2006 the earliest customers for AWS were high-end Hollywood effects studios, NVIDIA’s high-end customers include Pixar and a bunch of other leaders in the creation of fantasy. GTC is where they show off to the world with startling video clips, ergo a kind of narrative closure. NVIDIA also tends to focus on the very top of each business vertical.
NVIDIA is one of our customers at Derwen. Their company has made so many super-useful accomplishments. See: “Thinking Sparse and Dense”, recsys customer case studies, cuGraph integrations, etc.
https://derwen.ai/s/7wfbpdtb5t42
https://derwen.ai/s/89r853xbg2rn
Let’s unpack the notion of “Thinking Sparse and Dense” a bit… Since the 1990s in computing, we’ve been told how process is one of the most important parts of software engineering. That process is something general: it defines how teams build software for customers. Then software plays a kind of suzerainty to process: mutable mechanisms across layers of abstraction — but much less general than process. Meanwhile, hardware is a distant, obscure thing — pushed down several layers and rarely touched directly by software engineers.
Most product managers in software will nod ardently about all of the above, swearing up and down their team relies on Agile, etc., though out in the Real World™ we see the opposite.
Pro-tip: Hardware is evolving faster than software, and software is evolving faster than process. The industry trends optometrist says: “If you want to recognize what’s happening in AI, you’ll need this new pair of lenses.”
For a deep-dive exploring the GTC keynote, see Ben Lorica’s analysis:
https://gradientflow.com/nvidia-gtc-2024/
“NVIDIA’s shift from being primarily a chip provider to becoming a full-fledged platform provider, akin to tech giants like Microsoft or Apple, is a bold move that signals the company’s ambition to play a central role in shaping the AI ecosystem.”
Two of my key takeaways were Jensen Huang’s interstitial quips:
It’s interesting to compare with James Hamilton’s talk “Constraint-Driven Innovation” @ CIDR (2024-01-15): https://mvdirona.com/jrh/talksandpapers/JamesHamiltonCIDR2024.pdf
Hamilton is Chief Scientist at AWS and the retrospectives in this talk provide good details about ML training costs, power use, and so on — analyzed in terms of constraints imposed, then what happens when constraints get lifted.
One case caught my attention, to sketch what we’re seeing in AI training costs:
For historical reasons, I tend to believe Amazon’s published numbers more than anyone else.
There are curves which estimate these numbers, basically where physics (e.g., hardware constraints) drives cloud economics:
Similar to Mosaic’s Law above, the evolving (algorithmic) capabilities of models may help flatten these curves:
“Algorithmic progress in language models”
Anson Ho, et al. (2024-03-09)
https://arxiv.org/abs/2403.05812
“Using a dataset of over 200 language model evaluations on Wikitext and Penn Treebank spanning 2012–2023, we find that the compute required to reach a set performance threshold has halved approximately every 8 months, with a 95% confidence interval of around 5 to 14 months, substantially faster than hardware gains per Moore’s Law.”
Due to “chiplets” in hardware design, advances in compute resources far outpace advances in memory and storage, i.e. “CPU is moving further away from disk and memory.” IMO, there’s a big disconnect in system architectures vs. the economics of data lakes as a consequence. The keyword is connectivity. More about these hardware trends in a moment.
How do these economic curves line up for your application?
I have a confession to make … To lend a bit of backstory, someone close to me works in mental health. Sometimes we compare notes after work, for example:
“Wow, people at work were really crazy today, I mean REALLY crazy. You’d be amazed at what they were trying to pull…”
Me:
“Weird, I just got off a Zoom call, board meeting with VCs. Some investors were doing things similar to what you just described…”
For reference, in the former case we’re talking about a transition home with a dozen or so people who’ve recently been discharged from lockdown wards. Some have criminal insanity convictions for violent assault, because of voices in their heads, or something. They’re now “recovering” albeit living with serious psychotic disorders and heavily medicated, and they’re trying to qualify to live independently or in long-term group homes. Most are in conservatorships and have no personal spending money. Many are childlike: they crave having toys to play with, e.g., a Lego set, which they can’t afford.
I attend many technology conferences. Usually they give away “schwag” — Intel in particular loads guests with toys. So I used to make schwag donations at this transition home, donating toys to those who cannot afford them. Odd tech-ish freebies, a Magic Eight Ball from Intel marketing, various puzzles, and so on.
Unfortunately, things got out of hand.
In fact, we did have to call Security, although not to walk anyone out the door. Instead, someone had to go in through the door, grab said Magic Eight Ball, and then … RUN!!!
Because a group of people who were in fact psychotic had become fixated on randomized messages from Intel marketing:
Shake the ball, it proclaims “It’s the Siliconomy” … shake again to get “A Generational Shift in Computing” … then again “Empowering Developers to Bring AI Everywhere” and so on.
Steal the Magic Eight Ball with so much Intel Inside™ away from those who are upset about TAKING AWAY THEIR GOD.
Yeah, my bad.
The troubling part is the similarity measure, if you will, between this unusual experience and typical conversations with VCs about AI.
Thou doest beseech thine magickal palanteer and thus connecteth with thy god:
Shake the ball, it proclaims “$20M ARR” … shake again to get “Convertible note for preferred stock” … then again “20% cap table” … shake the unholy thing one more time to get “AI superintelligence” …
Pro-tip: seriously, you don’t ever want to trash-talk “superintelligences”, or engage in discussions about LLM fails, the worship of stochastic parrots, etc., not in front of these folks. They’ll get upset about someone taking away their god.
Speaking of late-stage capitalism …
firm | market capital ($T) | public cloud rev ($B) | search/recsys business share | ads revenue ($B) | hardware dev ($B) | surveillance data |
1.80 | 11% | 87% | 54.5 | 3.00 | ### | |
1.23 | 0% | ?? | 27.7 | 0.50 | ### | |
1.82 | 31% | 35% | - | 0.20 | ## | |
2.82 | 2% (or more?) | - | 85.0 | 8.09 | ### | |
1.97 | (secondary) | - | - | 60.92 | - | |
3.05 | 24% | 30% | 86.0 | ?? | ### | |
0.81 | (secondary) | - | - | 54.23 | - |
Notice how online marketing, AI, data collection, hardware R&D, etc., cluster together snuggly for trillion-dollar capitalizations? This is a “flywheel” effect, which we’ll revisit in just a bit.
“CFOs Tackle Thorny Calculus on Gen AI:
What’s the Return on Investment?”
Kristin Broughton, Mark Maurer
WSJ (2024-03-24)
https://www.wsj.com/articles/cfos-tackle-thorny-calculus-on-gen-ai-whats-the-return-on-investment-24ebf435
“In the next 12 months, 43% of U.S. companies with at least $1 billion in annual revenue expect to invest at least $100 million in generative AI.”
Senario: your large customers read Gartner, etc., anxious not to fall behind in the AI race … They’re suddenly eager to boost their cloud computing spend by 8 figures? Strike when the iron is hot, no matter how much you have to bend the rules!! From a corporate perspective as a hyperscaler, why not?
“Prayer, Prophecy, Prosperity”, Latent Space (2023) — illo: pxn
IMO one of the more glaring examples comes from GitHub CEO, Thomas Domke, who took time to write a “research paper” on the topic of using LLM-based copilots:
“Sea Change in Software Development: Economic and Productivity Analysis of the AI-Powered Developer Lifecycle”
Thomas Dohmke, Marco Iansiti, Greg Richards
Arxiv (2023-06-26)
https://arxiv.org/abs/2306.15033
… plus a related blog post:
https://github.blog/2023-06-27-the-economic-impact-of-the-ai-powered-developer-lifecycle-and-lessons-from-github-copilot/
These research claims from a Microsoft subsidiary are fascinating when compared with the recent GitClear report about the cumulative effects of copilots, which is research not online marketing: https://www.gitclear.com/coding_on_copilot_data_shows_ais_downward_pressure_on_code_quality
To wit, will the purported near-term satisfaction with copilots be shared by those who must maintain the code? Because the economics of copilots are currently upside w.r.t. software engineering needs. Keep in mind the quote from Robert Martin, author of Clean Code:
That said, LLMs are proving to be good at some code-related tasks, more on the side of providing tests, security patches, and suggested optimizations:
Throughout its history, speaking about the past ~75 years in particular, AI has mostly been intended to animate artifice, that is to say robots.
Something I don't say much in public: I am an animist. These practices embody my religious views. When I use the word `animate` I mean a broad context, one that affords the potential for language, thought, agency, personhood, volition, and so on among non-humans.
In so much of what’s been labeled as “AI” humans have sought to create a similar kind of agency embodied within artifice. There’s a deep desire to build robots, which we control, to do our bidding.
Understand that now, in this current generation of "AI", this breakthrough era which is dominated by hyperscalers that, more to the point, dominate online marketing ... (wait for it) ... We are the robots.
Our behaviors online are being driven by the hyperscalers, toward more engagement, more ad spend, more ecommerce, more upgrades, and so on. This is the major focus of large capital investments in “AI” currently: programming us as robots, as a kind of reverse animism.
For background, check this seminal text about cybernetics-meets-social-theory circa the Macy conferences:
The Human Use of Human Beings
Norbert Wiener
Houghton Mifflin (1950)
https://www.goodreads.com/book/show/153954.The_Human_Use_of_Human_Beings
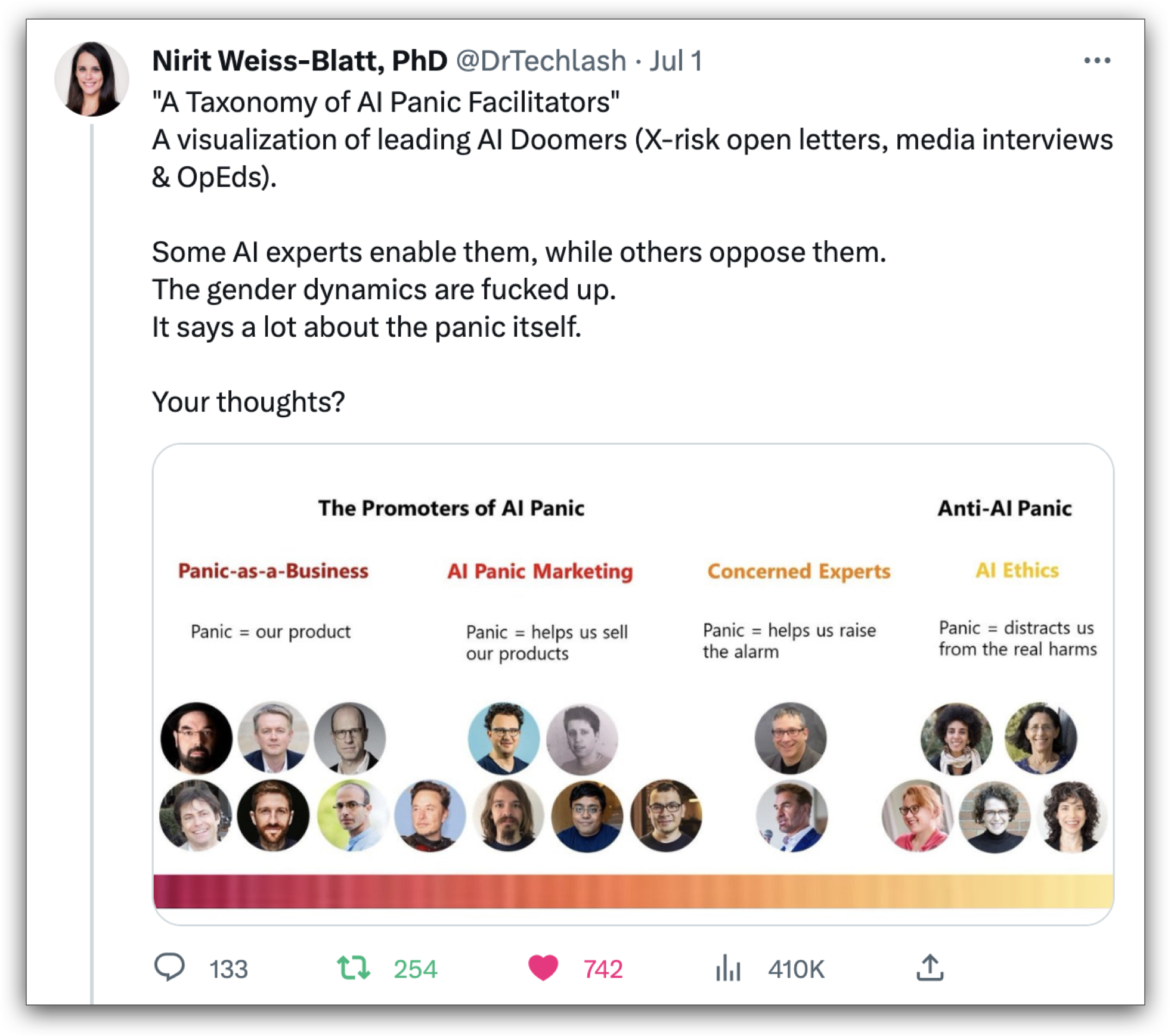
Ergo, see below: Torres, Gebru, Weiss-Blatt, Luccioni, et al.
To grok the full weirdness of Silicon Valley, you must first understand its quasi-religious currents. A notion called “Singularity” has been bubbling up for years. If you’ve never experienced the Singularity University — a non-accredited-not-actually-a-university co-founded by Google luminary Ray Kurzweil, located on a NASA base — well that’s probably one for the bucket list, eh? [ Have guest-lectured there twice, felt kinda dirty afterwards. ] Not to be confused with Singularity Institute (renamed MIRI) founded by people enthused about practices like misogyny, eugenics, insurrection, etc., who took issue with Kurzweil’s interpretations of “Singularity” due to their alleged ethical concerns, or something. [ Would not touch that place with a ten-foot pole. ]
In brief, the “Singularity” is about how machines will supposedly grow at uncontrollable rates, resulting in unforeseen consequences for human civilization. In other words, a bunch of billionaire tech bros in Silicon Valley who’d never actually watched Terminator thought it’d be way cool to claim they invented the plotline. Just search on Twitter/X for the letters `e/acc` in any user profile, you’ll find loads of accelerationist devotees.
Mark Pesce and Verner Vinge in the Next Billion Seconds studio (2019)
This whole kerfuffle traces back to a NASA report numbered “N94-27359”:
“The coming technological singularity:
How to survive in the post-human era”
Vernor Vinge
San Diego State University (1993-12-01)
https://ntrs.nasa.gov/citations/19940022856
“The acceleration of technological progress has been the central feature of this century. I argue in this paper that we are on the edge of change comparable to the rise of human life on Earth. The precise cause of this change is the imminent creation by technology of entities with greater than human intelligence.”
Vinge was a math professor, and also a renowned science fiction author. Mark Pesce interviewed Vinge about the origins of “Singularity” on the Next Billions Seconds podcast, which is highly recommended: https://nextbillionseconds.com/2024/03/22/vale-vernor-vinge-creator-of-a-technological-singularity-our-interview-from-2019/
It turns out that 1993 came nine years after 1984. Some might argue that Vinge got paid by NASA to paraphrase Cameron’s screenplay about SkyNet in academe-lingo, filling in more of the essential backstory. For example, John von Neumann used the term `singularity` related to human evolution back in the 1950s.
Vinge also charted potential paths toward “cataclysm” due to alleged super-human intelligence:
For kicks, let’s apply a circa 2024 decoder ring to update this list, courtesy of your friendly AI corporate optometrist:
In the tech industry, if you’re the kind of person who doesn’t write code or build products, and instead you’re some billionaire tech bro who tends to replay the first half of the movie Pretty Woman in your head over and over, while passing the days on social media … That is to say, someone who possesses a strong sense of entitlement and elite privilege, and (while we’re being candid) leans in close among circles of supremacy …
… okay, so then Door Number Three becomes your most likely choice for accelerating the advent of the Singularity. Vinge’s discussion of Übermensch-cum-AI-superintelligence would likely resonate, REALLY resonate personally. You’d probably assume that, naturally, YOU are that one special Übermensch destined to become augmented by an AI superintelligence, wielding domination über alles as the prophesized Kwisatz Haderach. Geez, you might even go out and buy a company focused on brain-computer interface implants, so you could get first in line to transcend the chains of human evolution.
Yeah, so that happened. Some people heard only the part of Vinge’s thesis they wanted to hear, not the caveats. Then they acted in earnest. This movement has snowballed into one of the main drivers for Silicon Valley.
“Entitled Tech Bros”, Latent Space (2023) — illo: pxn
Edge-lordly personae get TINGLES just thinking about Door Number Three! OH. MY. GOSH. Don’t get them started talking about it!
Most of their take boils down to “Let’s purge anyone who doesn’t look like / follow us” plus cryptic references to kinder, gentler second-wave eugenics. “We’re busy creating GOD! Don’t sweat the small stuff. Say, what if the entire Earth got totally wrecked and the upper crust had to relocate to, say, Mars, where some super-human billionaire tech bro could in fact rule the world?”
Because the Door Number Five super-human upgrades just aren’t happening soon enough. “Onward towards the promise of AGI Utopia, of course through the AGI Apocalypse first!”
In the Bay Area, it’s a lived experience.
We’ll delve further, more systematically, in one hot minute. Meanwhile, if you have anyone in your organization spewing this kind of `e/acc` Singularity-lurvin’ nonsense …
The drill: call Security, have them walked out the door, you’ll be glad you did.
The transformer architectures using attention mechanisms have been widely celebrated, with credit given to Google:
“Attention Is All You Need”
Ashish Vaswani, et al.
Google (2017-06-12)
arxiv.org/abs/1706.03762
“In this work we propose the Transformer, a model architecture eschewing recurrence and instead relying entirely on an attention mechanism to draw global dependencies between input and output. The Transformer allows for significantly more parallelization and can reach a new state of the art in translation quality after being trained for as little as twelve hours on eight P100 GPUs.”
Realistically, several different research teams were pursuing these kinds of ideas about attention mechanisms circa 2017. Google published first, and formally speaking they get credit for that.
For an excellent deep-dive into how transformers work, see:
“The Illustrated Transformer”
Jay Alammar
https://jalammar.github.io/illustrated-transformer/
Alammar (2020)
So much, so very much has been published about transformers and large language models (LLMs) in the intervening ~7 years, especially since OpenAI dropped ChatGPT in 2022. And while this technology is super useful, please recognize the astounding extent to which hyperbole has entered into this mix!
If you read one and only one primary source from this talk, please check this article about the TESCREAL bundle:
“The Acronym Behind Our Wildest AI Dreams and Nightmares”
Émile Torres
TruthDig (2023-06-15)
https://www.truthdig.com/articles/the-acronym-behind-our-wildest-ai-dreams-and-nightmares/
“At the heart of TESCREALism is a ‘techno-utopian’ vision of the future. It anticipates a time when advanced technologies enable humanity to accomplish things like: producing radical abundance, reengineering ourselves, becoming immortal, colonizing the universe and creating a sprawling ‘post-human’ civilization among the stars full of trillions and trillions of people. The most straightforward way to realize this utopia is by building superintelligent AGI.”
If you go next-level on background reading and try at least two primary sources, then check The Techlash and the Tech Crisis Communication by Nirit Weiss-Blatt.
x.com/DrTechlash/status/1675155157880016898
As Weiss-Blatt explains, there’s rampant, widespread (manufactured) AI Panic, because … on the one hand AI will cause utter Doom … or on the other hand because not accelerating technology fast enough causes humanity to miss out on AI’s saving graces. I’m calling BS. It’s a false dichotomy which currently drives trillions in economic flows, based on … well, we’ll deconstruct their BS in just a moment.
For now, some of your best resources for your AI optometry are:
Is this important? IMO, oh f’heck yeah! For example, Ethereum’s crypto-coin poster boy Vitalik Buterin arranged a half-bil donation to an AI Panic lobby called the “Future of Life Institute” which has been up to all kinds of trouble: https://www.linkedin.com/pulse/how-vitalik-buterin-kickstarted-ai-activism-michael-spencer-f9ztc/
A philosophy that permeates the TESCREAL bundle is Effective Altruism, the argument that earned Sam Bankman Fried a 25-year prison sentence with an $11B forfeiture. That said, this once high-flying “philosophy” appears to be in its death throes.
Pro-tip: many of the loud voices making AGI arguments were selling fraudulent crypto coins this time last year, or are closely adjacent to people who wear “88” neck tattoos, or both.
This leads us to an important set of criteria for critical reading strategies, much like learning to use poker tells:
Interestingly, when you take the `TELL` out of `AI SUPERINTELLIGENCES` you get:
( … wait for it … )
`LITERAL PENIS EUGENICS`
No subtlety. That’s just overt.
Taking cues from my dad, a Persian mathematician and poet, anagrams are our preferred flavor of Magic Eight Ball.
“Mis En Place”, Latent Space (2023) — illo: Heath Rezabek
Part of the problem is that actual neural networks in messy animal brains are immensely complex. I’m grateful to have been involved with the CodeNeuro events (2015-2016) led by Jeremy Freeman. The gist: neurophysiologists who wanted to learn more about machine learning and data science would gather for weekends in SF or NYC to collaborate, a couple times each year. We learned lots of trippy mind-blowing things, although the one that made my skin crawl most was “Neural Circuits for Skilled Movement” by Eiman Azim @ Columbia.
Have a good listen. You may find that arguments about transformers bringing about AGI look iffy.
To frame this more clearly, please listen to the following and be sure to take notes:
“Systems that learn and reason”
Frank Van Harmelen
Connected Data podcast (2024-04-01)
https://pod.co/the-connected-data-podcast/systems-that-learn-and-reason-frank-van-harmelen
Van Harmelen spells out quite succinctly how there’s been a long-standing division between one camp focused on “symbolic AI” (concept) vs. another camp focused on “statistical AI” (sensory), where they don’t talk much. A pendulum effect in AI research swings between these extremes within a period of about a decade. Symbolic approaches suffer from their need for human effort, while statistical approaches tend to get “data hangry” in ways that may not work out so well in the long run.
Van Harmelen (2024)
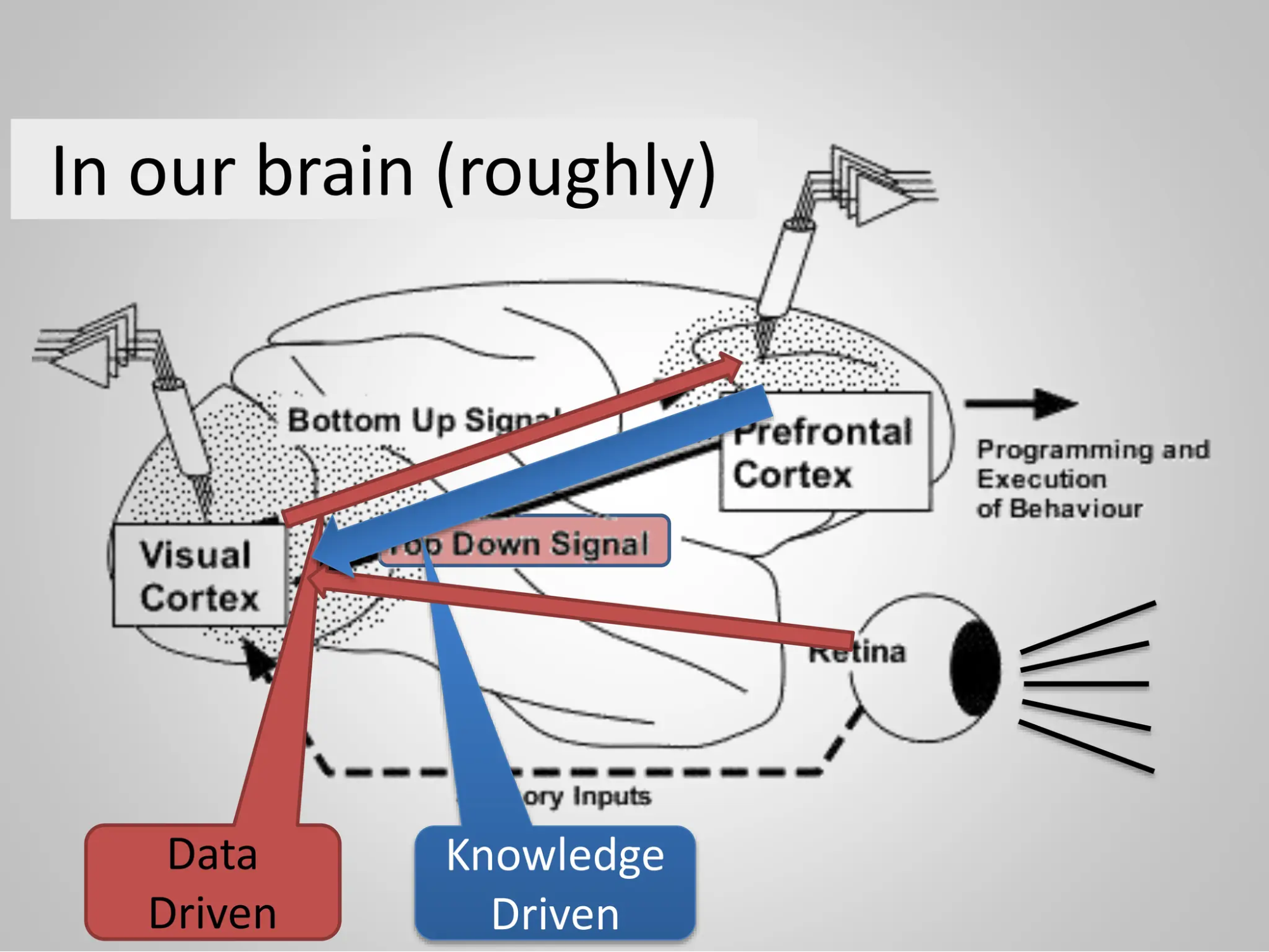
Looking at actual neurophysiology research, while yes animal brains make big biological investments in structures akin to LLMs for processing sensory input, real brains make even larger investments in managing “downstream signals” about which concepts to expect. Real intelligence is embodied, and it plays with time. A visual cortex in animals wouldn’t run fast enough without a fine balance of this symbolic/sensory dual architecture, as crucial feedback loops. Recall what Maturana taught us about cognition and feedback loops?
The current generation of machine learning focused on LLMs and generative AI is missing the symbolic interface with the Latent Space. Use of retrieval-augmented generation (RAG) plays a kind of band-aid to fix LLMs with duct tape and bailing wire. The analogy: pouring more money into a bad investment probably isn’t going to make you rich.
Hyperscalers and their proxies (OpenAI) which now claim to be “on the verge of AGI” have carefully selected (read: cherry-picked) examples to make the case that their work on the statistical end of the spectrum will dominate über alles.
However, both the symbolic and the statistical camps of AI have advanced greatly over the past decade, although practitioners on either side tend to be unaware. That bodes well, although don’t hold your breath for even a hybrid approach to initiate a glorious AGI future.
BTW, notice where Van Harmelen mentions using a hybrid approach called a semantic loss-function on the podcast? Non-hyperscalers in industry have been sniffing down this trail of cookie crumbs. For deets, check out work by a guy named Guy Van den Broeck who leads the StarAI lab at UCLA. Remember these names.
“A Semantic Loss Function for Deep Learning with Symbolic Knowledge”
Jingyi Xu, Zilu Zhang, Tal Friedman, Yitao Liang, Guy Van den Broeck
ICML (2018-06-08)
arxiv.org/abs/1711.11157
Meanwhile, non-ironic uses of the term “AGI” circa 2024 are suspect. Definitions are slippery at best. Such a thing does not exist. Arguments claiming that current generation machine learning will get us there Real Soon™ are specious. Ibid., online marketing hubris meets investor relations to prop trillion-dollar stock valuations. On NASDAQ, we used to call this “pump and dump” but maybe things have changed?
Less-informed individuals who’ve suddenly/recently rebranded themselves as “AI Experts” tend to say that “Google invented AI in 2017, before that it was just machine learning.” Their ilk also tends to equate “AI” with chat bots.
In practice, the term “AGI” is very slippery. I don’t feel comfortable with any predictions there. It has also become a dog whistle for a bundle of subtly related political creeds. It’s shorthand for: “Whatever it takes to accelerate the Singularity!” Because actual adults — mostly super-wealthy white guys — concocted a bundle of pseudo-religions based on coke-addled misreads of the plotlines for B-rate (or C-rate, probably more like D-rate) SciFy movies. Now they’re shoving trillions of dollars around the planet, trying to lure the masses to scan their retinas in a crypto-coin scam, funding far-right candidates for US Senate, and so on. Stated agendas push misogyny, racism, and other bigotries justified to generate more wealth — based on views constructed precariously atop aristotelian extrapolations about technology and Lord of the Flies misinterpretations of “evolution” that would render even Ayn Rand speechless. A cursory reading of Karl Popper is enough to tear this entire TESCREAL bundle to pieces.
The drill: call Security, have them walked out the door, you deserve better.
A curious dynamic emerged in the tech industry, circa late-2010s, after the exemplars for the term “hyperscaler” had become unmistakably apparent. Following the mid-1990s popularity of the Internet and the rise of ecommerce, a strange kind of business “flywheel” dynamic appeared … and nearly seized control.
Rolling back a few decades, mainframe computers (1940s-ff) used relatively simple “input/output” notions of interaction. Our notions of online “communities” were absent, even networking was extremely limited. This changed in the late-1960s with new notions of internetworking and the launch of ARPAnet, followed in 1971 by the introduction of email.
My former employer, AT&T, had agreed with the US federal government not to enter into any computing business directly, in exchange for being allowed to operate as a legal monopoly for telephone service in the US. However, at the same time that Ray Tomilson was hacking together the first email service on a PDP minicomputer, Ken Thompson and Dennis Ritchie at AT&T Bell Labs were experiencing withdrawal symptoms. They’d been re-assigned off an MIT collaboration called MULTICS — from which AT&T withdrew due to project delays and cost overruns. MULTICS provided means for multiple users to be online at the same time, interacting with each other. Jonesing for that community platform, Thompson and Ritchie grabbed an unused PDP at Bell Labs and in their spare moments invented both Unix and the C programming language. Yep, bog-standard nerds dearly missed their proto-Slack dopamine fix, circa 1969.
Unix use cases grew inside Bell Labs, then outside at universities as well. AT&T couldn’t appear to sell software, fearing antitrust fines, so the user communities emerging around Unix were provided with updates surreptitiously. UC Berkeley leveraged DARPA funding to create their own “Berkeley Software Distribution” variant of Unix, and the ensuing legal fray in the 1990s led to an O’Reilly Media event later renamed the Open Source Summit — with many parties aligning (más o menos) on our contemporary definitions for open source.
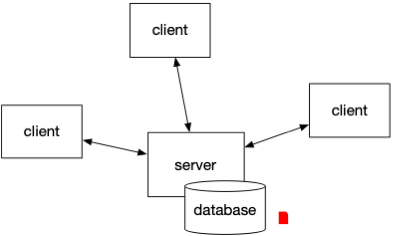
User communities and interactions over networks gave rise to Client-Server Architecture: users worked on client systems (terminals or PCs) and data was stored in databases on the server side. Data governance notions were immature, and mostly confined to login security and database administration.
During 1997-1998, four industry teams arrived at similar conclusions independently. The idea of Three-Tier Architecture had overtaken Client-Server for the new generation of ecommerce: instead of a terminal, the client side split into (1) a web application which served user interactions through (2) web browsers, and meanwhile databases on the server side grew rather large. Oracle was becoming the dominant database vendor, and their aggressive pricing strategies loomed over the nascent ecommerce firms due to an odd dichotomy:
Revenue generally grows when you scale from a thousand paying customers to a million. In contrast the statistical distribution of events in web logs for a well-functioning ecommerce system doesn’t change much when your log archives grow 1000x. Even so, infrastructure costs — and Oracle licensing — scale in both cases. ROI for analytics gets upside down.
Pro-tip: the negative-ROI relation can be inverted by leveraging analytics infra to generate data products, then used to train ML models which expand business opportunities. This approach only works when the cost/performance curves can be carefully finessed, which we’ll touch on later.
During 1997-1998, teams at Amazon, Yahoo!, eBay, and Google realized that Oracle would price their business models out of existence. They innovated around the problem:
Greg Linden and team split the Amazon ecommerce web application into a distributed system, growing their cluster to a whopping count of FOUR SERVERS! They pushed their results into production just in time to handle the historic December 1997 ecommerce tsunami, which propelled the hyperscalers into becoming a thing.
To move away from using commercial databases to capture web interaction data, Linden, Brewer, Shoup, et al., collected customer interaction events into semi-structured log files. Data governance drove this need for log files: security, anti-fraud, failure post-mortems, potential legal actions, and so on.
As product managers became interested in A/B testing for ecommerce applications during the 2000s, R&D teams learned to run data mining on web logs — establishing early notions of data products. Data science team practices emerged circa 2009, I led some of those early identified teams. Like many others, we created ML models based on data products mined from customer interactions, then deployed our models into recommender systems and similar use cases to drive ecommerce engagement, fight credit card fraud, etc.
”Sci vs. Sci”, Joseph Turian, Strata conference (2013)
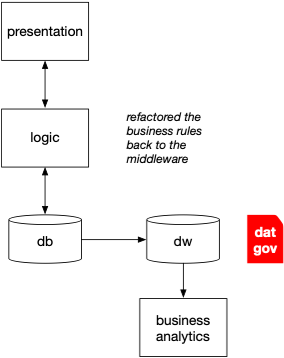
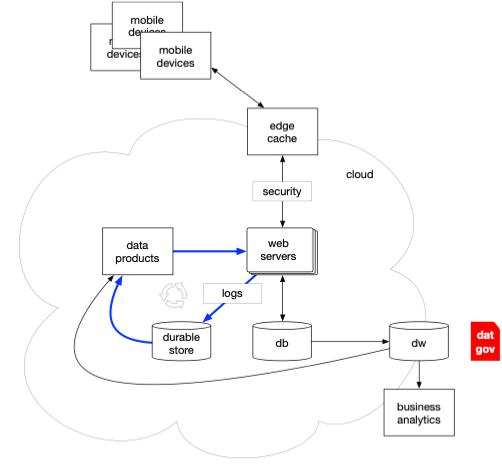
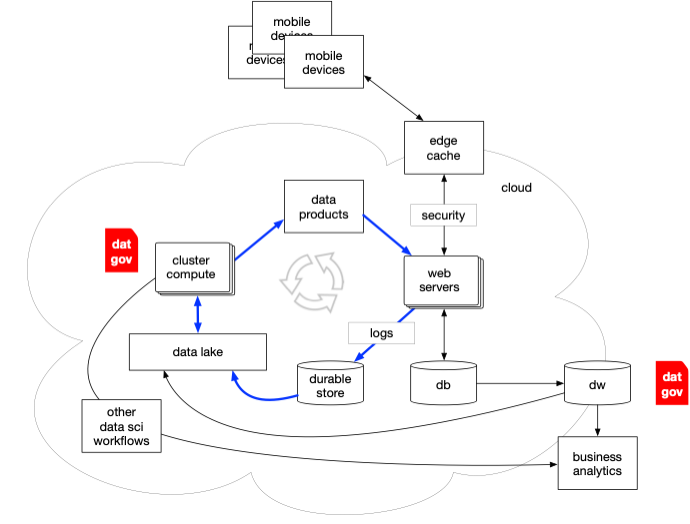
This evolution created a “flywheel” effect (aka, a “virtuous cycle”) where ML-powered ecommerce features led to enormous log file archives, which made data products grow, resulting in better ML models, and so on. Note in the following depicts how data governance grew with each new pattern introduced.
Pro-tip: each of the following “eras” experienced a latency period of a few years before new software architecture patterns diffused out to mainstream adoption.
1970s and before: mainframes
1980s: client/server architecture
1990s: three-tier architecture leveraged for ecommerce
2000s: cloud-based “virtuous cycle” flywheel effect begins to emerge
2010s: machine learning applications gain broad adoption
2020s: generative AI — you are here
The evolution of this “flywheel” is what lured us toward the current era of Generative AI. Again, most of this has been focused among the hyperscalers, and quite frankly their interests in using AI is to program the robots en masse, i.e., us.
So where is this headed?
“The hype conjures itself into existence via hardware advances.”
— Andrew Padilla
Understand that infrastructure had to become increasingly distributed through the years to handle the growing demands of speed and scale. Big Data approaches evolved to wrangle massive volumes of data. Cloud computing evolved from those split web servers at Amazon, etc.,, resulting in computing grids and storage grids (such as EC2 and S3).
Two papers describe this evolution brilliantly. Breiman in 2001 covered the cultural shift about data and machine learning during the late-1990s — away from people who looked like my 1980s Statistics professors dressed in three-piece suits, toward ML engineers wearing snarky, ironic t-shirts. Patterson, et al., in 2009 introduced analysis of the physics driving the economics of cloud computing. [ Latter got this AWS guinea pig invited to guest-lecture at UC Berkeley, and the paper’s co-authors became future colleagues at Databricks. ]
“Statistical Modeling: The Two Cultures”
Leo Breiman
Statistical Science (2001-08-01)
https://doi.org/10.1214/ss/1009213726
Subsequent commentary:
https://academic.oup.com/jrssig/article/17/1/34/7029453?login=false
“Above the Clouds: A Berkeley View of Cloud Computing”
Michael Armbrust, Armando Fox, Rean Griffith, Anthony Joseph, Randy Katz, Andrew Konwinski, Gunho Lee, David Patterson, Ariel Rabkin, Ion Stoica, Matei Zaharia
UC Berkeley EECS (2009-02-10)
https://www2.eecs.berkeley.edu/Pubs/TechRpts/2009/EECS-2009-28.html
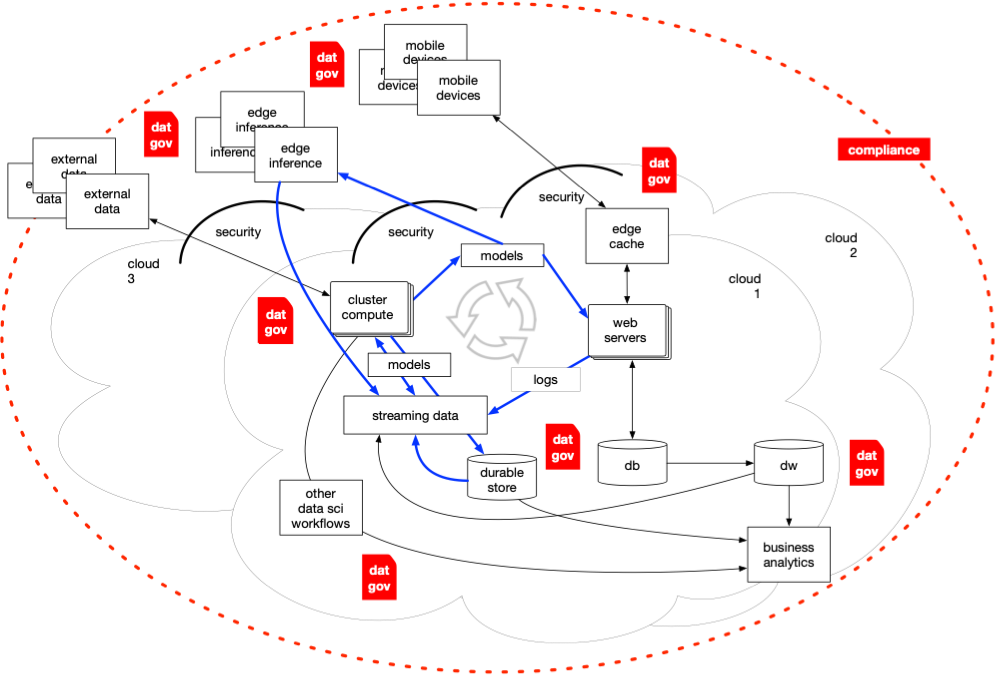
Pro-tip: Make no mistake, the priorities of data governance are still dominant factors driving the evolution of data and AI.
Today we see apps (or even models) spread across multiple clouds. Many compelling concerns about data privacy, AI ethics and safety, needs to mitigate bias, contending with sustained global cyberattacks, and so on create an environment where the hyperscalers must be regulated. Our team works a lot in Europe, and frankly the fallout from GDPR has benefited the tech industry greatly, especially for startups. Trust — which Rachel Botsman describes as “a confident relationship with the unknown” — pays big dividends.
Cultural aspects that Breiman and others pointed out decades ago continue to drive AI evolution, and data governance practices typically follow. There will be winners and losers in this game, and judging from recent events, some of the top hyperscalers appear to be clustering among the latter.
The physics/economics issues which led to cloud computing, which led to AI applications, and so forth, etc., continue to drive evolution in this field. If you were paying attention during the rise of Big Data and tooling such as Apache Spark, the thing we kept teaching everyone was: distributed processing of data parallel tasks is relatively easy, while distributed processing of aggregation tasks is really difficult! And really expensive!!!
“Up on the Big Screen”, Latent Space (2023) — illo: Heath Rezabek
Aggregation is the part where multiple compute units, which have been running independently in parallel, suddenly must change tack and talk amongst themselves. Connectivity and concurrency are really difficult tasks in computing.
Understand that machine learning algorithms have two major components: a loss function and a regularization term. For neural networks, the loss function must be computed across all gazillion elements, and probably computed again at every layer in the “deeply” layered neural network architecture. Therefore, training an LLM from scratch circa early-2020s cost ~$100M, if you had an expert team (also expensive) and they did their work correctly on the first attempt (which rarely happens).
Connectivity is what puts large, distributed machine learning projects at risk. Compute requirements (e.g., “How many thousands of GPUs?”) make for attractive headlines in popular media — or VC investment pitch decks, or Wall Street analysts calls — but the reality in 2024 is that compute chiplets are pretty well known and relatively easy to place on a silicon wafer. Connecting those compute units beyond a particular scale exceeds the bounds of known physics. This is why Jensen Huang boasts now that “A GPU is an entire rack.” This is also why you might want to watch carefully at what comes out from an NVIDIA competitor called AMD. Enough said, although two excellent interviewers explore these deets:
“The AI Infrastructure Revolution: From Cloud Computing to Data Center Design”
Ben Lorica
The Data Exchange (2024-02-22)
https://thedataexchange.media/oxide-computer/
“The future of AI chips: Leaders, dark horses and rising stars”
George Anadiotis
Linked Data Orchestration (2024-02-29)
https://linkeddataorchestration.com/2024/02/13/the-future-of-ai-chips-leaders-dark-horses-and-rising-stars/
We could wrap the talk on this point, but let’s push further…
Among hyperscalers, following the rise of transformers among research, two things about Microsoft became clear in the late-2010s. First, they were a trillion-dollar company, which is impressive. Second, while they had great results streaming out of Microsoft Research, among the hyperscalers Microsoft may have placed 4th or 5th in terms of AI capabilities, if we’re being generous. Despite their acquisition/integration of GitHub, the Azure cloud computing service was full of fails.
Short of having been a fly on the wall during MSFT Board meetings in 2018-ish, it’s glaringly apparent how these financial risks were becoming a problem for the company. Wall Street analysts dislike when a multi-$T firm doesn’t place first or second in their category — makes it tough for institutional investors to think coherently. Redmond needed a big win.
Microsoft structured a deal with OpenAI in 2019, initially investing $1B, with another $12B cumulative investment by 2023: https://www.cnbc.com/2023/04/08/microsofts-complex-bet-on-openai-brings-potential-and-uncertainty.html
Early years of OpenAI, originally founded as a non-profit, have been described in Bay Area tech social circles as “an excuse to go over to Greg’s apartment and get really baked.” Of course the company produced good engineering results, such as DALL•E 2, Whisper, etc.
After the Microsoft deal, OAI positioning took on a different bent: spotlighting celebrity CEO Sam Altman’s habit of climbing on a soapbox to spew colorfully. Whenever Altman steps up to a virtual megaphone, pontificating about AI superintelligences (or his McLarens, ancient alien astronauts, or what-evs) asserting the real-soon-ish eventuality of OpenAI achieving “AGI” … Alphabet execs lose their minds. They panic in Mountain View, while Satya Nadella and his corporate besties snicker all the way to the bank. Works like a charm.
For example, Quoc Le — lead author of the famous “cat” image recognition paper at Google, and one of Andrew Ng’s grad students who introduced deep learning into the company — warned internally about OpenAI’s ChatGPT. Mainstream press reported this as a “Code Red” where Alphabet execs urged an all-hands-on-deck response.
Two years prior, Alphabet had fired their entire AI Ethics team over their warning not to release chat bots prematurely. Which made sense, given it was precisely the hyperscaler mistake that got Microsoft into Nazi-loving hot water over Tay. Regardless, after OpenAI dropped ChatGPT on the world and proclaimed about eventual AGI-ness, Alphabet execs lost their minds! In early 2023, in response to their own “Code Red” panic, they did the very thing Timnit Gebru and the AI ethics team members had been fired for warning against. Alphabet fast-tracked release of Bard, and its demo in front of Reuters amounted to a face-plant, resulting in a $100B drop in GOOG market cap during single-day trading. Because super-genius, or superintelligences, or something.
Here’s the Reuters article (2023-02-08): https://www.reuters.com/technology/google-ai-chatbot-bard-offers-inaccurate-information-company-ad-2023-02-08/
Wall Street analysts raised concerns that Alphabet was losing ground to rival Microsoft. Done and done.
A joke around Silicon Valley is that Alphabet product managers struggle to find their way out of a wet paper bag. Earning $400K/yr with free lattes included is already so much work, who needs to build good products in response to market demand?? Like, literally just can’t even. The Bard kerfuffle helped cement this impression.
Pro-tip: from the POV of Microsoft execs, system functioning as intended.
But have Microsoft and OpenAI made tangible advances in AI? You decide.
There’s a stream of open source, papers, etc., though otherwise the open source AI models have steadily climbed up the leaderboards and dominate on price/performance for many scenarios. OpenAI’s $80B valuation is looking iffy, we’ll surely get more weird soapbox rants from Altman. Microsoft has initiated strategic deals with OAI competitors, though in any case Redmond printed money through this deal.
What Microsoft pulled off is the corporate equivalent of an elaborate poker bluff. Born out of desperation, their multi-trillion-dollar hail mary paid handsomely: playing both ends against the middle. Wall Street analysts aren’t often rocket geniuses, few have the technical chops to begin to parse the massive sleight-of-hand tricks in play. They parrot the phrase “AGI” which they’ve read in press releases due to online marketing or from Gartner.
Beyond the hyperscalers’ online marketing / investor relations hype … there are legit examples of AI applications in industry. We have a quite few tools in the tool bag for this:
Where do LLMs fit in this tool box? Often you’ll hear the large language models characterized as unsupervised learning. Translated in business terms: take trillions of input data elements, gathered from across the Internet web pages, then automagically have a model build itself. But that’s not quite how things tend to work.
Language models pull a few neat tricks. One is learning how to map sequences of things to other sequences of things, leveraging the attention mechanisms we’ve mentioned. This is great for language syntax, since there are many examples to be found … so then the sequences within the input data lend the ability to use self-supervised learning, which is complex but it does lean toward the automagical side. Another neat trick is diffusion: take a whole thing (such as an image) and randomly knockout parts, replaced with noise. Repeat until the whole thing is just noise. Then reverse the sequence, so that you have noise => signal. Then train models to correct for noise. This may be image data (e.g., DALL•E 2) or may be data that’s more complex, such as corporate strategic plans.
Here are my two favorite papers (so far) for explaining why and how, and where the limitations and potentials seem to be:
“A Latent Space Theory for Emergent Abilities in Large Language Models”
Hui Jiang
York U (2023-09-13)
https://arxiv.org/abs/2304.09960
“We categorize languages as either unambiguous or ε-ambiguous and present quantitative results to demonstrate that the emergent abilities of LLMs, such as language understanding, in-context learning, chain-of-thought prompting, and effective instruction fine-tuning, can all be attributed to Bayesian inference on the sparse joint distribution of languages.”
“Are Emergent Abilities of Large Language Models a Mirage?”
Rylan Schaeffer, Brando Miranda, Sanmi Koyejo
Stanford (2023–05–22)
https://arxiv.org/abs/2304.15004
“We call into question the claim that LLMs possess emergent abilities, by which we specifically mean sharp and unpredictable changes in model outputs as a function of model scale on specific tasks.”
And, in memoriam:
“Getting from Generative AI to Trustworthy AI: What LLMs might learn from Cyc”
Doug Lenat, et al. (2023-07-31)
arxiv.org/abs/2308.04445
“Current LLM-based chatbots aren’t so much understanding and inferring as remembering and espousing…”
Within the space of open source AI models there’s been loads of work to identify ways to improve LLM training, fine-tuning, inference, etc. Full-disclosure, I’m on the Board of Argilla.io which works closely with Hugging Face and other related orgs, especially in these aspects. Since December 2023, so much of the activity on the HF leaderboards has been about using variants of RLHF methods where reinforcement learning, weak supervision, and other parts of the AI tool box get used together.
Translated: someone else spent millions $$$ to train an LLM using loads of GPUs. You use their data but fix it, then fine-tune a derived LLM without even needing GPUs, … et voilà you get the better LLM! Then leap-frog the creators of the original model on the leaderboard.
Pro-tip: there’s more ROI in fixing the data (removing bad training examples, rebalancing synthetic data with domain experts’ feedback, iterating on benchmarks, evals, testing criteria, etc.) than in twiddling algorithms ad nauseam.
A sampler for some of favorite examples of AI applications:
Survey of AlphaFold, material discovery, contagion models, etc.
https://arxiv.org/abs/2402.16887
Ding, et al., (2024)
Skylight by AI2 for integrating lots of complex signals to track vessels at sea, e.g., used by governments world wide to catch illegal fishing, smuggling, etc.
https://www.skylight.global/
Weather and climate forecasts @ CalTech: 45000x faster than current weather models, while having the same accuracy
http://tensorlab.cms.caltech.edu/users/anima/
Beer (in Belgium) https://www.theguardian.com/technology/2024/mar/26/ai-beer-taste-better-belgium-scientists
https://www.nature.com/articles/s41467–024–46346–0
see related:
https://arxiv.org/abs/1303.4402
https://snap.stanford.edu/class/cs224w–2015/projects_2015/Community_Detection_&_Network_Analysis_for_Beer_Recommendations.pdf
Emirates Team New Zealand + QuantumBlack AI designs win America’s Cup https://www.mckinsey.com/featured-insights/future-of-asia/future-of-asia-podcasts/teaching-ai-to-sail-like-a-world-class-sailor-and-what-it-means-for-business
https://thedataexchange.media/reinforcement-learning-in-real-world-applications/
“Personalized Audiobook Recommendations at Spotify Through Graph Neural Networks”
Marco De Nadai, et al.
ACM (2024–03–08)
https://arxiv.org/abs/2403.05185
Hardware drives this. Industry examples of AI use cases in production tend to lag the hardware advances because:
Looking ahead at near-term business outlook, I tend to lean toward what Andrew Ng described in “Opportunities in AI — 2023”:
Be patient, breathe. Something’s emerging, though we need to approach this carefully…
In Mel Richey’s brilliant keynote talk at the 2023 Senzing user conference, she employed the phrase “vapors of the human experience”, which is a callback to Snow Crash by Neal Stephenson. Highly recommended.
“Regardless of your discipline and domain I contend that everyone here is working on the same basic challenge which is how do we distill understanding and prediction from the vapors of The Human Experience and the data sets that our sensors collect within it?”
— Mel Richey
Here’s an exercise, a ritual if you will, about the Latent Space:
Close your eyes. Breathe. Imagine many different kinds of “surfaces” where traces of human exchange have collected. The “vapors” which record our existence. Written language, or spoken. This communication could be in the form of drawings and visual depictions, paintings, films, t-shirts, bumper stickers. Or in terms of textures, music, dance. Orchestra performances, operas. Sign language! Could be some mixture of all of the above. For each instance of medium, there are ways to “tokenize” these communications: into words, phonemes, signals, frames, the segmented foreground of an image, etc. Exhale. You can open your eyes now.
Large language models are fed data from a process of harvesting these surfaces. LLMs “learn” to recognize relationships between these tokens. Tokenized data from one medium can also have relationships with tokenized data from another medium, e.g., how we use “prompt” phrases to generate images — this is called multimodal.
For example, if I say “Run, Spot, …” you probably respond with the final “Run” word. LLMs are really good at doing just that. It’s a capability which can be manipulated in many useful ways. This is precisely what people are calling “AI” in the media headlines.
Understand that these learned sequences of tokens and the relationships among them are syntax. The process of learning sequences does not necessarily imply any deeper levels of cognition. However, it does evoke a sense of what we call the Latent Space. The one thing which LLMs do startlingly well is to learn to recognize syntax — in dramatically more accurate ways than we’d seen from any artifice before. What had previously been ~70% accurate might now be 98% accurate, or some-such depending on the context. And, given enormous scale, this effect tends to leverage self-supervised learning, for yet another glimpse of making magic happen … automagically.
Ibid., Van Harmelen, who hinted at this process. LLMs get HANGRY for data, and this is both a strength and a weakness. It’s how Alphabet, Meta, Apple, etc., have carefully cherry-picked examples through elaborate corporate strategy, then conducted wars against each other within the realm of published academic papers about their AI projects — making claims which are nearly impossible to be verified independently due to scale, costs, proprietary system architectures, etc. Ibid., Popper’s well-tempered warnings.
“Akkadian Priesthood.”, Latent Space (2023) — illo: Chris Joseph
If you haven’t spent years navigating the tangled pathways and darkened corners of Western Esoteric Tradition, aka “the occult”, let’s just say there’s a well-known problem. This problem applies now in the tech industry for business people trying to learn about AI.
Some percentage of the human population — maybe as much as 5% — when confronted with automagical phenomena beyond their kin to mansplain immediately will respond with a devout experience of having encountered a god. Vernacular for this is “Trip like I do.” Chat bots are currently fitting into the automagical phenomena category — or some imagined future version. A tangible percentage will glimpse a sleight-of-hand trick, then dive off the deep end in a big hurry. The transition home looms ahead.
Suppose we had Michaelangelo here today and asked him to sculpt ten different figures representing Venus. The results might all be different, each uniquely beautiful, yet all evoking our concept of Venus.
We could ask other artists to portray Venus, again in a myriad of different unique representations, but all sharing some essence. We could ask dancers to perform a Venus in a physical, moving sense.
These are all ideas, manifest in physical representations. While the possible manifestations of Venus might seem infinite, there is some central concept, some essence.
In the field of AI, we say that the Latent Space is where these concepts dwell. Millions, billions, trillions of data elements go into training large models. Within that data some finite number of concepts gets represented. Many concepts will be trained from multiple examples and a process of generalizing from them is the essence of the “learning” in machine learning.
We also talk about lower dimensional embeddings, where the lowest dimension ostensibly represents approximations of the finite number of concepts which the model has learned.
If you want a great story about this topic, I recommend Résumé with Monsters by William Browning Spencer. His sci fi novel is about a print shop in Central Texas, where FringeWare used to be a customer.
Spoiler alert: higher dimensional Cthulhoid beings discover how to manifest into our world via photo-copiers … then Austin gets weird!
Does a linkage between LLMs learning relationships among tokens — the process which lends us glimpses into the Latent Space — represent anything other than syntax and statistics? Probably not. Although it begs some intriguing questions.
If you’ve been paying attention to what it is that LLMs do well, versus what they don’t particularly do well, the idea of using a domain-specific language (DSL) may have crossed your mind. DSLs were all the rage for a hot minute back circa Big Data, and you can find good open source libraries in Python, etc. They provide constrained languages (syntax, really) to describe things within a particular domain. It’s a convenient way of “meeting in the middle” with LLMs currently.
Related to this, in addition to Jiang2023, check out:
“From Word Models to World Models: Translating from Natural Language to the Probabilistic Language of Thought”
Lionel Wong, et al.
Arxiv (2023-06-23)
https://arxiv.org/abs/2306.12672
Don’t bet the farm that chat will be the primary mode of interaction for AI apps. Beginning in about February 2023, many upper executives across the Global 2000 began spending A LOT of time playing with ChatGPT. Some plan to spend at least $100M this year to keep playing for a high score. Many have been candid about their thinking:
Yeah, this is the mediocre corporate executive version of Door Number Three. Execs want to be augmented, they want their very own, closely-held, tightly-controlled version of the Singularity which Vinge described and Altman promised.
Except that few execs daydreaming this fantasy have done the math. If THOUSANDS of people with MBAs can ask their own personal Magic Eight Ball how to outcompete the other THOUSANDS – 1 MBAs, then guess what? There will be no barrier to entry. Fall back below the noise as super-geniuses, or superintelligences, or something.
Instead of fixating on chat bots (which over-emphasize only half of the needed neural architectures to accomplish the impossible) why not do something pragmatic?
A dirty little secret within the Industrial AI community is that the typical "last-mile" of AI use cases in industry tends to prepare data for use in decision support, e.g., operations research, causal inference, business process, and so on. Expect these latter areas (ORSA, causal graphs, etc.) to benefit substantially from the massive capital investments currently pouring into hardware for AI. Hardware cost/performance curves are changing rapidly. It’s likely that these not-ML technologies for decision support will be among the most direct beneficiaries.
Speaking of being pragmatic, it just pains me to hear people talk about AI as if they needed to swap out the transmission on their F–150:
“We’re fixin’ to head over to AutoZone. Gonna buy some of them dual overhead-cam attention head layers. Maybe a decoupled variational one-hot autoencoder, depending on what’s on sale.”
It’s more likely to be the case that you’d weld together 10,000 transmissions and get rid of the engine and wheels. Or something. But the “Mr. Fixit” analogies for work in machine learning, these gadget fetishes just don’t work. The nuts and bolts are evolving too rapidly.
What does pay is to dig into the math. During the early stages of almost any civilization-changing technology shift, the solutions tend to be exotic. Look at how much digital computers changed in the arc between diode tubes and solid-state circuits. This has been true for many complex technologies: electrical power grids, nuclear weapons development, resilient airframes, and so on.
What generally happens is that after a few years of bizarrely ad-hoc experimentation, the mathematicians arrive and begin to restate the complex bits of the problem in terms of algebraic objects, joint probability distributions, etc. Check out any of the major defense contractors in the US design next-generation military aircraft: there’s loads of simulations, optimizations, and so on. Organizations use solvers to run optimizations and perform risk analysis, and then inform large capital investments. Again, hardware windfalls will likely boost this effect.
In the case of currently popularized notions of "AI" — i.e., large transformer models with astoundingly improved abilities for sequence-to-sequence learning, diffusion, etc. —
the underlying technology is literally based on algebraic objects and joint probability distributions (see Van den Broek, et al., below) so we can expect the later-stage math to work well for making quick work of the current generation of LLMs, etc.
Here’s some light reading. which IMO will become important for leveraging AI applications in industry in the very near-term:
“Understanding the Distillation Process from Deep Generative Models to Tractable Probabilistic Circuits”
Xuejie Liu, Anji Liu, Guy Van den Broeck, Yitao Liang
ICML (2023-02-16)
https://starai.cs.ucla.edu/papers/LiuICML23.pdf
“Topological structure of complex predictions”
Meng Liu, Tamal K. Dey, David Gleich
Purdue (2022-10-20)
https://arxiv.org/abs/2207.14358
WeightWatcher — statistical mechanics used to analyze AI models
Charles Martin, et al.
https://weightwatcher.ai/
Notwithstanding all the shade I’ve thrown at the billionaire tech bros vying to become the centerfold in next year’s “Men of TESCREAL” pin-up calendar: they aren’t all wrong. Some germ of truth is hidden deep in their Singularity nonsense…
“ISHTAR: Intel., Survei., HUMINT, Target Acq., Recon.”, Latent Space (2023) — illo: Chris Joseph
Circa 1993, there was an attorney hanging around our FringeWare-ish social circles in Austin, who proposed a brilliant thought experiment:
“Let’s form a private corporation which only owns two assets: a computer driving a chat bot, plus a financial endowment to cover its operational costs in perpetuity. We’ll add the chat bot to the Board of Directors. Then have the remainder of the (human) BoD members resign.”
So does that bot then own itself?
From a legal perspective, does it exercise agency?
This siren song beguiled me, circa Dot Com Bust, toward a line of inquiry … an unusual analysis of “AI”, and now these odd notions from 25 years ago become important for understanding AI in business. Perhaps best summarized by outcomes from an online forum we called “The Ceteri Institute”:
Corporate law in the US creates elaborate mechanisms to evoke entities, embodied with agency and constructed from artifice — specifically from DSL-ish formalized language — which are nearly self-perpetuating. Not entirely, but hey among publicly traded firms, some of these artifices are now over 400 years old.
Tickling the Latent Space, mining surfaces of discourse among intelligent beings, self-supervised learning at trillion scale and its aftermath we see so vividly now, plus the notions of manifold theory, higher dimensional reasoning, and lower order embeddings ... our pursuits of AI, especially among systems/communities of automated agents, these blur the lines between AI and corporate entities.
The stranger aspects of AI, notions about Singularity, corporate entities, and so on. These do in fact closely resemble something: what medieval authors described as demonology. Evocation based on special names and symbols/logos, commanding artifices which are being fed by the offerings of attention from groups of us mere mortals — corporate law, or demonology?
Spoiler alert: Shira Chess, a professor of Media Studies at the University of Georgia, has a book out soon which covers several topics here in detail. Highly recommended!
That demon driving a red F–750 at excessive speeds in the MoPac Express Lane, the one in the monster truck with all the AMG aftermarket mods, spewing enormous clouds of smoke? That’s the one. His name’s Beelzebubba.
You may need to adjust your lenses so you can peek through the sulfur and flying brimstone. But if you listen very hard, you might just hear Beezlebubba’s utterances amidst the cursing and eerie soundtrack:
“Yup, we’re fixin’ to head over to AutoZone” … “Lemme go get my Magic Eight Ball” …
(Enochian incantation ensues)
“Emergency on Planet Earth”, Latent Space (2023) — illo: pxn
If you’re in business and now trying to learn about AI, odds are good that you’ve been hoodwinked to some degree by people pretending to be supergeniuses, who are also busy siphoning off boatloads of cash. Odds are high that vendors, analysts, etc., may try to help push this hoodwinking further. Check for known dog whistles, then clean house.
Instead, a sane approach to current conditions in AI appears to be: pursue a policy of developing trust, i.e., a confident relationship with the Unknown. The recommended take-aways from this alternative POV are:
Thank you, you’ve been very kind.
Related resources in which Derwen is involved:
Client projects:
Upcoming conferences:
Copyright © 2024, Derwen, Inc. All rights reserved, except fair use excerpts and illustrations as attributed. This does not constitute investment advice.