Note
To run this notebook in JupyterLab, load examples/ex2_0.ipynb
Build a medium size KG from a CSV dataset¶
First let's initialize the KG object as we did previously:
import kglab
namespaces = {
"wtm": "http://purl.org/heals/food/",
"ind": "http://purl.org/heals/ingredient/",
"skos": "http://www.w3.org/2004/02/skos/core#",
}
kg = kglab.KnowledgeGraph(
name = "A recipe KG example based on Food.com",
base_uri = "https://www.food.com/recipe/",
namespaces = namespaces,
)
Here's a way to describe the namespaces that are available to use:
kg.describe_ns()
| prefix | namespace | |
|---|---|---|
| 0 | dct | http://purl.org/dc/terms/ |
| 1 | owl | http://www.w3.org/2002/07/owl# |
| 2 | prov | http://www.w3.org/ns/prov# |
| 3 | rdf | http://www.w3.org/1999/02/22-rdf-syntax-ns# |
| 4 | rdfs | http://www.w3.org/2000/01/rdf-schema# |
| 5 | schema | http://schema.org/ |
| 6 | sh | http://www.w3.org/ns/shacl# |
| 7 | xsd | http://www.w3.org/2001/XMLSchema# |
| 8 | wtm | http://purl.org/heals/food/ |
| 9 | ind | http://purl.org/heals/ingredient/ |
| 10 | skos | http://www.w3.org/2004/02/skos/core# |
| 11 | xml | http://www.w3.org/XML/1998/namespace |
Next, we'll define a dictionary that maps (somewhat magically) from strings (i.e., "labels") to ingredients defined in the http://purl.org/heals/ingredient/ vocabulary:
common_ingredient = {
"water": kg.get_ns("ind").Water,
"salt": kg.get_ns("ind").Salt,
"pepper": kg.get_ns("ind").BlackPepper,
"black pepper": kg.get_ns("ind").BlackPepper,
"dried basil": kg.get_ns("ind").Basil,
"butter": kg.get_ns("ind").Butter,
"milk": kg.get_ns("ind").CowMilk,
"egg": kg.get_ns("ind").ChickenEgg,
"eggs": kg.get_ns("ind").ChickenEgg,
"bacon": kg.get_ns("ind").Bacon,
"sugar": kg.get_ns("ind").WhiteSugar,
"brown sugar": kg.get_ns("ind").BrownSugar,
"honey": kg.get_ns("ind").Honey,
"vanilla": kg.get_ns("ind").VanillaExtract,
"vanilla extract": kg.get_ns("ind").VanillaExtract,
"flour": kg.get_ns("ind").AllPurposeFlour,
"all-purpose flour": kg.get_ns("ind").AllPurposeFlour,
"whole wheat flour": kg.get_ns("ind").WholeWheatFlour,
"olive oil": kg.get_ns("ind").OliveOil,
"vinegar": kg.get_ns("ind").AppleCiderVinegar,
"garlic": kg.get_ns("ind").Garlic,
"garlic clove": kg.get_ns("ind").Garlic,
"garlic cloves": kg.get_ns("ind").Garlic,
"onion": kg.get_ns("ind").Onion,
"onions": kg.get_ns("ind").Onion,
"cabbage": kg.get_ns("ind").Cabbage,
"carrot": kg.get_ns("ind").Carrot,
"carrots": kg.get_ns("ind").Carrot,
"celery": kg.get_ns("ind").Celery,
"potato": kg.get_ns("ind").Potato,
"potatoes": kg.get_ns("ind").Potato,
"tomato": kg.get_ns("ind").Tomato,
"tomatoes": kg.get_ns("ind").Tomato,
"baking powder": kg.get_ns("ind").BakingPowder,
"baking soda": kg.get_ns("ind").BakingSoda,
}
This is where use of NLP work to produce annotations begins to overlap with KG pratices.
Now let's load our dataset of recipes – the dat/recipes.csv file in CSV format – into a pandas dataframe:
from os.path import dirname
import os
import pandas as pd
df = pd.read_csv(dirname(os.getcwd()) + "/dat/recipes.csv")
df.head()
| id | name | minutes | tags | description | ingredients | |
|---|---|---|---|---|---|---|
| 0 | 164636 | 1 1 1 tempura batter | 5 | ['15-minutes-or-less', 'time-to-make', 'course... | i use this everytime i make onion rings, hot p... | ['egg', 'flour', 'water'] |
| 1 | 144841 | 2 step pound cake for a kitchen aide mixer | 110 | ['time-to-make', 'course', 'preparation', 'occ... | this recipe was published in a southern living... | ['flour', 'sugar', 'butter', 'milk', 'eggs', '... |
| 2 | 189437 | 40 second omelet | 25 | ['30-minutes-or-less', 'time-to-make', 'course... | you'll need an "inverted pancake turner" for t... | ['eggs', 'water', 'butter'] |
| 3 | 19104 | all purpose dinner crepes batter | 90 | ['weeknight', 'time-to-make', 'course', 'main-... | this basic crepe recipe can be used for all yo... | ['eggs', 'salt', 'flour', 'milk', 'butter'] |
| 4 | 64793 | amish friendship starter | 14405 | ['weeknight', 'time-to-make', 'course', 'cuisi... | this recipe was given to me years ago by a fri... | ['sugar', 'flour', 'milk'] |
Then iterate over the rows in the dataframe, representing a recipe in the KG for each row:
import rdflib
for index, row in df.iterrows():
recipe_id = row["id"]
node = rdflib.URIRef("https://www.food.com/recipe/{}".format(recipe_id))
kg.add(node, kg.get_ns("rdf").type, kg.get_ns("wtm").Recipe)
recipe_name = row["name"]
kg.add(node, kg.get_ns("skos").definition, rdflib.Literal(recipe_name))
cook_time = row["minutes"]
cook_time_literal = "PT{}M".format(int(cook_time))
code_time_node = rdflib.Literal(cook_time_literal, datatype=kg.get_ns("xsd").duration)
kg.add(node, kg.get_ns("wtm").hasCookTime, code_time_node)
ind_list = eval(row["ingredients"])
for ind in ind_list:
ingredient = ind.strip()
ingredient_obj = common_ingredient[ingredient]
kg.add(node, kg.get_ns("wtm").hasIngredient, ingredient_obj)
Notice how the xsd:duration literal is now getting used to represent cooking times.
We've structured this example such that each of the recipes in the CSV file has a known representation for all of its ingredients.
There are nearly 250K recipes in the full dataset from https://food.com/ so the common_ingredient dictionary would need to be extended quite a lot to handle all of those possible ingredients.
At this stage, our graph has grown by a couple orders of magnitude, so its visualization should be more interesting now. Let's take a look:
VIS_STYLE = {
"wtm": {
"color": "orange",
"size": 20,
},
"ind":{
"color": "blue",
"size": 35,
},
}
subgraph = kglab.SubgraphTensor(kg)
pyvis_graph = subgraph.build_pyvis_graph(notebook=True, style=VIS_STYLE)
pyvis_graph.force_atlas_2based()
pyvis_graph.show("tmp.fig01.html")
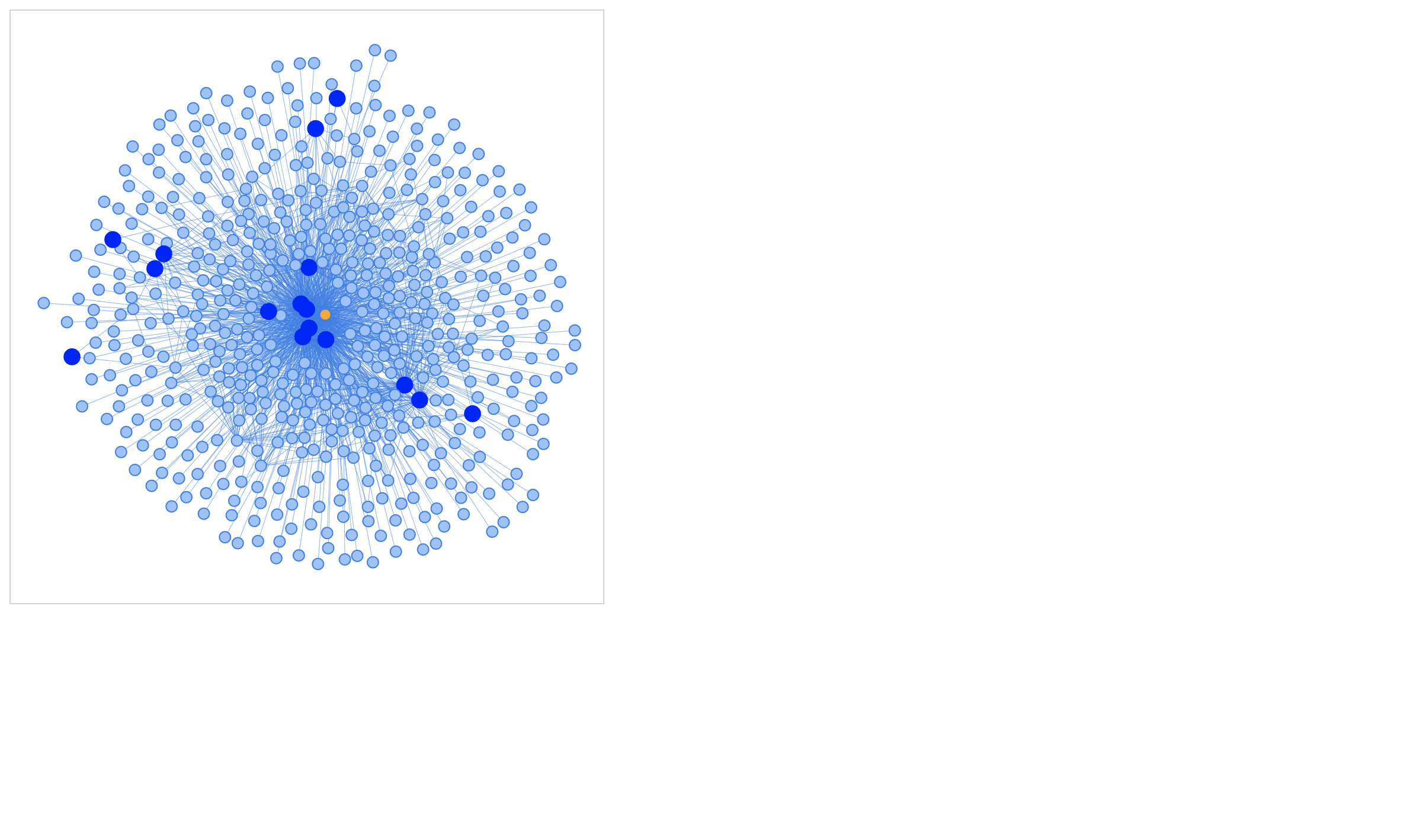
Given the defaults for this kind of visualization, there's likely a dense center mass of orange (recipes) at the center, with a close cluster of common ingredients (dark blue), surrounded by less common ingredients and cooking times (light blue).
Performance analysis of serialization methods¶
Let's serialize this recipe KG constructed from the CSV dataset to a local TTL file, while measuring the time and disk space required:
import time
write_times = []
t0 = time.time()
kg.save_rdf("tmp.ttl")
write_times.append(round((time.time() - t0) * 1000.0, 2))
Let's also serialize the KG into the other formats that we've been using, to compare relative sizes for a medium size KG:
t0 = time.time()
kg.save_rdf("tmp.xml", format="xml")
write_times.append(round((time.time() - t0) * 1000.0, 2))
t0 = time.time()
kg.save_jsonld("tmp.jsonld")
write_times.append(round((time.time() - t0) * 1000.0, 2))
t0 = time.time()
kg.save_parquet("tmp.parquet")
write_times.append(round((time.time() - t0) * 1000.0, 2))
file_paths = ["tmp.ttl", "tmp.xml", "tmp.jsonld", "tmp.parquet"]
file_sizes = [os.path.getsize(file_path) for file_path in file_paths]
df = pd.DataFrame({"file_path": file_paths, "file_size": file_sizes, "write_time": write_times})
df["ms_per_byte"] = df["write_time"] / df["file_size"]
df
| file_path | file_size | write_time | ms_per_byte | |
|---|---|---|---|---|
| 0 | tmp.ttl | 56780 | 116.03 | 0.002044 |
| 1 | tmp.xml | 159397 | 42.04 | 0.000264 |
| 2 | tmp.jsonld | 131901 | 92.12 | 0.000698 |
| 3 | tmp.parquet | 14710 | 37.76 | 0.002567 |
Notice the relative sizes and times? Parquet provides for compression in a way that works well with RDF. The same KG stored as a Parquet file is ~10% the size of the same KG stored as JSON-LD. Also the XML version is quite large.
Looking at the write times, Parquet is relatively fast (after its first invocation) and its reads are faster. The eponymous Turtle format is human-readable although relatively slow. XML is fast to write, but much larger on disk and difficult to read. JSON-LD is interesting in that any JSON library can read and use these files, without needing semantic technologies, per se; however, it's also large on disk.
Exercises¶
Exercise 1:
Select another ingredient in the http://purl.org/heals/ingredient/ vocabulary that is not in the common_ingredient dictionary, for which you can find at least one simple recipe within https://food.com/ searches.
Then add this recipe into the KG.