Note
To run this notebook in JupyterLab, load examples/ex8_0.ipynb
Vector embedding with gensim¶
Let's make use of deep learning through a technique called embedding – to analyze the relatedness of the labels used for recipe ingredients.
Among the most closely related ingredients:
- Some are very close synonyms and should be consolidated to improve data quality
- Others are interesting other ingredients that pair frequently, useful for recommendations
On the one hand, this approach is quite helpful for analyzing the NLP annotations that go into a knowledge graph.
On the other hand it can be used along with SKOS or similar vocabularies for ontology-based discovery within the graph, e.g., for advanced search UI.
Curating annotations¶
We'll be working with the labels for ingredients that go into our KG. Looking at the raw data, there are many cases where slightly different spellings are being used for the same entity.
As a first step let's define a list of synonyms to substitute, prior to running the vector embedding. This will help produce better quality results.
Note that this kind of work comes of the general heading of curating annotations ... which is what we spend so much time doing in KG work. It's similar to how data preparation is ~80% of the workload for data science teams, and for good reason.
SYNONYMS = {
"pepper": "black pepper",
"black pepper": "black pepper",
"egg": "egg",
"eggs": "egg",
"vanilla": "vanilla",
"vanilla extract": "vanilla",
"flour": "flour",
"all-purpose flour": "flour",
"onions": "onion",
"onion": "onion",
"carrots": "carrot",
"carrot": "carrot",
"potatoes": "potato",
"potato": "potato",
"tomatoes": "tomato",
"fresh tomatoes": "tomato",
"fresh tomato": "tomato",
"garlic": "garlic",
"garlic clove": "garlic",
"garlic cloves": "garlic",
}
Analyze ingredient labels from 250K recipes¶
from os.path import dirname
import csv
import os
MAX_ROW = 250000 # 231638
max_context = 0
min_context = 1000
recipes = []
vocab = set()
with open(dirname(os.getcwd()) + "/dat/all_ind.csv", "r") as f:
reader = csv.reader(f)
next(reader, None) # remove file header
for i, row in enumerate(reader):
id = row[0]
ind_set = set()
# substitute synonyms
for ind in set(eval(row[3])):
if ind in SYNONYMS:
ind_set.add(SYNONYMS[ind])
else:
ind_set.add(ind)
if len(ind_set) > 1:
recipes.append([id, ind_set])
vocab.update(ind_set)
max_context = max(max_context, len(ind_set))
min_context = min(min_context, len(ind_set))
if i > MAX_ROW:
break
print("max context: {} unique ingredients per recipe".format(max_context))
print("min context: {} unique ingredients per recipe".format(min_context))
print("vocab size", len(list(vocab)))
max context: 43 unique ingredients per recipe
min context: 2 unique ingredients per recipe
vocab size 14931
Since we've performed this data preparation work, let's use pickle to save this larger superset of the recipes dataset to the tmp.pkl file:
import pickle
pickle.dump(recipes, open("tmp.pkl", "wb"))
recipes[:3]
[['137739',
{'butter',
'honey',
'mexican seasoning',
'mixed spice',
'olive oil',
'salt',
'winter squash'}],
['31490',
{'cheese',
'egg',
'milk',
'prepared pizza crust',
'salt and pepper',
'sausage patty'}],
['112140',
{'cheddar cheese',
'chili powder',
'diced tomatoes',
'ground beef',
'ground cumin',
'kidney beans',
'lettuce',
'rotel tomatoes',
'salt',
'tomato paste',
'tomato soup',
'water',
'yellow onions'}]]
Then we can restore the pickled Python data structure for usage later in other use cases. The output shows the first few entries, to illustrated the format.
Now reshape this data into a vector of vectors of ingredients per recipe, to use for training a word2vec vector embedding model:
vectors = [
[
ind
for ind in ind_set
]
for id, ind_set in recipes
]
vectors[:3]
[['mexican seasoning',
'winter squash',
'salt',
'olive oil',
'mixed spice',
'honey',
'butter'],
['cheese',
'sausage patty',
'milk',
'salt and pepper',
'egg',
'prepared pizza crust'],
['lettuce',
'rotel tomatoes',
'diced tomatoes',
'water',
'yellow onions',
'tomato soup',
'ground cumin',
'salt',
'cheddar cheese',
'kidney beans',
'ground beef',
'tomato paste',
'chili powder']]
We'll use the Word2Vec implementation in the gensim library (i.e., deep learning) to train an embedding model.
This approach tends to work best if the training data has at least 100K rows.
Let's also show how to serialize the word2vec results, saving them to the tmp.w2v file so they could be restored later for other use cases.
!pip install gensim
!pip install pylev
Requirement already satisfied: gensim in /Users/paco/src/kglab/venv/lib/python3.7/site-packages (4.1.2)
Requirement already satisfied: numpy>=1.17.0 in /Users/paco/src/kglab/venv/lib/python3.7/site-packages (from gensim) (1.21.2)
Requirement already satisfied: scipy>=0.18.1 in /Users/paco/src/kglab/venv/lib/python3.7/site-packages (from gensim) (1.7.1)
Requirement already satisfied: smart-open>=1.8.1 in /Users/paco/src/kglab/venv/lib/python3.7/site-packages (from gensim) (5.2.1)
Requirement already satisfied: pylev in /Users/paco/src/kglab/venv/lib/python3.7/site-packages (1.4.0)
import gensim
MIN_COUNT = 2
model_path = "tmp.w2v"
model = gensim.models.Word2Vec(vectors, min_count=MIN_COUNT, window=max_context)
model.save(model_path)
The get_related() function takes any ingredient as input, using the embedding model to find the most similar other ingredients – along with calculating levenshtein edit distances (string similarity) among these labels. Then it calculates percentiles for both metrics in numpy and returns the results as a pandas DataFrame.
import numpy as np
import pandas as pd
import pylev
def term_ratio (target, description):
d_set = set(description.split(" "))
num_inter = len(d_set.intersection(target))
return num_inter / float(len(target))
def get_related (model, query, target, n=20, granularity=100):
"""return a DataFrame of the closely related items"""
try:
bins = np.linspace(0, 1, num=granularity, endpoint=True)
v = sorted(
model.wv.most_similar(positive=[query], topn=n),
key=lambda x: x[1],
reverse=True
)
df = pd.DataFrame(v, columns=["ingredient", "similarity"])
s = df["similarity"]
quantiles = s.quantile(bins, interpolation="nearest")
df["sim_pct"] = np.digitize(s, quantiles) - 1
df["levenshtein"] = [ pylev.levenshtein(d, query) / len(query) for d in df["ingredient"] ]
s = df["levenshtein"]
quantiles = s.quantile(bins, interpolation="nearest")
df["lev_pct"] = granularity - np.digitize(s, quantiles)
df["term_ratio"] = [ term_ratio(target, d) for d in df["ingredient"] ]
return df
except KeyError:
return pd.DataFrame(columns=["ingredient", "similarity", "percentile"])
Let's try this with dried basil as the ingredient to query, and review the top 50 most similar other ingredients returned as the DataFrame df:
target = set([ "basil" ])
df = get_related(model, "dried basil", target, n=50)
df
| ingredient | similarity | sim_pct | levenshtein | lev_pct | term_ratio | |
|---|---|---|---|---|---|---|
| 0 | dried basil leaves | 0.677376 | 99 | 0.636364 | 78 | 1.0 |
| 1 | dry basil | 0.618740 | 97 | 0.272727 | 98 | 1.0 |
| 2 | dried rosemary | 0.605385 | 95 | 0.636364 | 78 | 0.0 |
| 3 | dried sweet basil leaves | 0.593628 | 93 | 1.181818 | 34 | 1.0 |
| 4 | dried italian seasoning | 0.581919 | 91 | 1.272727 | 30 | 0.0 |
| 5 | fresh basil | 0.574703 | 89 | 0.363636 | 96 | 1.0 |
| 6 | italian herb seasoning | 0.548939 | 87 | 1.454545 | 16 | 0.0 |
| 7 | italian seasoning | 0.538376 | 85 | 1.090909 | 48 | 0.0 |
| 8 | dried marjoram | 0.533788 | 83 | 0.636364 | 78 | 0.0 |
| 9 | dried parsley | 0.518489 | 81 | 0.454545 | 92 | 0.0 |
| 10 | dried rosemary leaves | 0.509467 | 79 | 1.181818 | 34 | 0.0 |
| 11 | dried parsley flakes | 0.508277 | 77 | 1.000000 | 58 | 0.0 |
| 12 | italian seasoning mix | 0.471910 | 75 | 1.454545 | 16 | 0.0 |
| 13 | basil | 0.470737 | 73 | 0.545455 | 90 | 1.0 |
| 14 | italian spices | 0.464688 | 71 | 1.090909 | 48 | 0.0 |
| 15 | italian sausage | 0.453568 | 69 | 1.000000 | 58 | 0.0 |
| 16 | fresh basil leaves | 0.451666 | 67 | 1.000000 | 58 | 1.0 |
| 17 | quick-cooking barley | 0.451440 | 65 | 1.454545 | 16 | 0.0 |
| 18 | fresh basil leaf | 0.450319 | 63 | 0.818182 | 72 | 1.0 |
| 19 | italian sausages | 0.448237 | 61 | 1.090909 | 48 | 0.0 |
| 20 | globe eggplants | 0.447171 | 59 | 1.181818 | 34 | 0.0 |
| 21 | dried thyme leaves | 0.445578 | 57 | 1.000000 | 58 | 0.0 |
| 22 | hunts tomato paste | 0.445030 | 55 | 1.363636 | 24 | 0.0 |
| 23 | dried red pepper flakes | 0.442688 | 53 | 1.454545 | 16 | 0.0 |
| 24 | dried whole thyme | 0.442518 | 51 | 1.000000 | 58 | 0.0 |
| 25 | button mushroom | 0.441169 | 49 | 1.181818 | 34 | 0.0 |
| 26 | fresh mushrooms | 0.440132 | 47 | 1.090909 | 48 | 0.0 |
| 27 | lasagna noodles | 0.432072 | 45 | 1.181818 | 34 | 0.0 |
| 28 | mild italian sausage | 0.430874 | 43 | 1.363636 | 24 | 0.0 |
| 29 | sliced mushrooms | 0.429246 | 41 | 1.000000 | 58 | 0.0 |
| 30 | herb seasoning mix | 0.424856 | 39 | 1.363636 | 24 | 0.0 |
| 31 | dry oregano | 0.423101 | 37 | 0.818182 | 72 | 0.0 |
| 32 | pitted black olives | 0.418710 | 35 | 1.181818 | 34 | 0.0 |
| 33 | rubbed sage | 0.418236 | 33 | 0.727273 | 76 | 0.0 |
| 34 | frozen chopped spinach | 0.416980 | 31 | 1.545455 | 12 | 0.0 |
| 35 | dried italian herb seasoning | 0.415891 | 29 | 1.636364 | 8 | 0.0 |
| 36 | dried thyme | 0.413673 | 27 | 0.454545 | 92 | 0.0 |
| 37 | part-skim mozzarella cheese | 0.411310 | 25 | 2.090909 | 0 | 0.0 |
| 38 | chianti wine | 0.410693 | 23 | 0.909091 | 70 | 0.0 |
| 39 | thin spaghetti | 0.409562 | 21 | 1.090909 | 48 | 0.0 |
| 40 | italian style breadcrumbs | 0.409037 | 19 | 1.909091 | 4 | 0.0 |
| 41 | hot pepper flakes | 0.405416 | 17 | 1.272727 | 30 | 0.0 |
| 42 | sweet italian sausage | 0.405204 | 15 | 1.545455 | 12 | 0.0 |
| 43 | orzo pasta | 0.404851 | 13 | 0.636364 | 78 | 0.0 |
| 44 | dried tarragon | 0.403677 | 11 | 0.636364 | 78 | 0.0 |
| 45 | yolk-free wide egg noodles | 0.403116 | 9 | 1.909091 | 4 | 0.0 |
| 46 | ziti pasta | 0.402639 | 7 | 0.636364 | 78 | 0.0 |
| 47 | cannellini beans | 0.401280 | 5 | 1.181818 | 34 | 0.0 |
| 48 | contadina diced tomatoes | 0.400817 | 3 | 1.636364 | 8 | 0.0 |
| 49 | italian-style diced tomatoes | 0.398550 | 1 | 2.090909 | 0 | 0.0 |
Note how some of the most similar items, based on vector embedding, are synonyms or special forms of our query dried basil ingredient: dried basil leaves, dry basil, dried sweet basil leaves, etc. These tend to rank high in terms of levenshtein distance too.
Let's plot the similarity measures:
!pip install matplotlib
Requirement already satisfied: matplotlib in /Users/paco/src/kglab/venv/lib/python3.7/site-packages (3.4.3)
Requirement already satisfied: pillow>=6.2.0 in /Users/paco/src/kglab/venv/lib/python3.7/site-packages (from matplotlib) (8.3.2)
Requirement already satisfied: cycler>=0.10 in /Users/paco/src/kglab/venv/lib/python3.7/site-packages (from matplotlib) (0.10.0)
Requirement already satisfied: pyparsing>=2.2.1 in /Users/paco/src/kglab/venv/lib/python3.7/site-packages (from matplotlib) (2.4.7)
Requirement already satisfied: numpy>=1.16 in /Users/paco/src/kglab/venv/lib/python3.7/site-packages (from matplotlib) (1.21.2)
Requirement already satisfied: python-dateutil>=2.7 in /Users/paco/src/kglab/venv/lib/python3.7/site-packages (from matplotlib) (2.8.1)
Requirement already satisfied: kiwisolver>=1.0.1 in /Users/paco/src/kglab/venv/lib/python3.7/site-packages (from matplotlib) (1.3.2)
Requirement already satisfied: six in /Users/paco/src/kglab/venv/lib/python3.7/site-packages (from cycler>=0.10->matplotlib) (1.15.0)
import matplotlib
import matplotlib.pyplot as plt
matplotlib.style.use("ggplot")
df["similarity"].plot(alpha=0.75, rot=0)
plt.show()
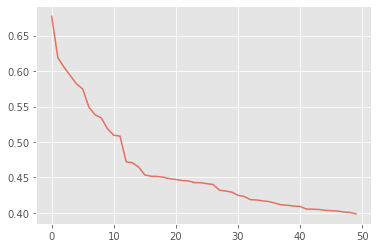
Notice the inflection points at approximately 0.56 and again at 0.47 in that plot.
We could use some statistical techniques (e.g., clustering) to segment the similarities into a few groups:
- highest similarity – potential synonyms for the query
- mid-range similarity – potential hypernyms and hyponyms for the query
- long-tail similarity – other ingredients that pair well with the query
In this example, below a threshold of the 75th percentile for vector embedding similarity, the related ingredients are less about being synonyms and more about other foods that pair well with basil.
Let's define another function rank_related() which ranks the related ingredients based on a combination of these two metrics.
This uses a cheap approximation of a pareto archive for the ranking -- which comes in handy for recommender systems and custom search applications that must combine multiple ranking metrics:
from kglab import root_mean_square
def rank_related (df):
df2 = df.copy(deep=True)
df2["related"] = df2.apply(lambda row: root_mean_square([ row[2], row[4] ]), axis=1)
return df2.sort_values(by=["related"], ascending=False)
df = rank_related(df)
df
| ingredient | similarity | sim_pct | levenshtein | lev_pct | term_ratio | related | |
|---|---|---|---|---|---|---|---|
| 1 | dry basil | 0.618740 | 97 | 0.272727 | 98 | 1.0 | 97.501282 |
| 5 | fresh basil | 0.574703 | 89 | 0.363636 | 96 | 1.0 | 92.566193 |
| 0 | dried basil leaves | 0.677376 | 99 | 0.636364 | 78 | 1.0 | 89.120705 |
| 2 | dried rosemary | 0.605385 | 95 | 0.636364 | 78 | 0.0 | 86.916627 |
| 9 | dried parsley | 0.518489 | 81 | 0.454545 | 92 | 0.0 | 86.674679 |
| 13 | basil | 0.470737 | 73 | 0.545455 | 90 | 1.0 | 81.942053 |
| 8 | dried marjoram | 0.533788 | 83 | 0.636364 | 78 | 0.0 | 80.538811 |
| 3 | dried sweet basil leaves | 0.593628 | 93 | 1.181818 | 34 | 1.0 | 70.017855 |
| 7 | italian seasoning | 0.538376 | 85 | 1.090909 | 48 | 0.0 | 69.025358 |
| 11 | dried parsley flakes | 0.508277 | 77 | 1.000000 | 58 | 0.0 | 68.165240 |
| 36 | dried thyme | 0.413673 | 27 | 0.454545 | 92 | 0.0 | 67.797493 |
| 4 | dried italian seasoning | 0.581919 | 91 | 1.272727 | 30 | 0.0 | 67.753229 |
| 18 | fresh basil leaf | 0.450319 | 63 | 0.818182 | 72 | 1.0 | 67.649834 |
| 15 | italian sausage | 0.453568 | 69 | 1.000000 | 58 | 0.0 | 63.737744 |
| 16 | fresh basil leaves | 0.451666 | 67 | 1.000000 | 58 | 1.0 | 62.661791 |
| 6 | italian herb seasoning | 0.548939 | 87 | 1.454545 | 16 | 0.0 | 62.549980 |
| 10 | dried rosemary leaves | 0.509467 | 79 | 1.181818 | 34 | 0.0 | 60.815294 |
| 14 | italian spices | 0.464688 | 71 | 1.090909 | 48 | 0.0 | 60.601155 |
| 33 | rubbed sage | 0.418236 | 33 | 0.727273 | 76 | 0.0 | 58.587541 |
| 21 | dried thyme leaves | 0.445578 | 57 | 1.000000 | 58 | 0.0 | 57.502174 |
| 31 | dry oregano | 0.423101 | 37 | 0.818182 | 72 | 0.0 | 57.240720 |
| 43 | orzo pasta | 0.404851 | 13 | 0.636364 | 78 | 0.0 | 55.915114 |
| 44 | dried tarragon | 0.403677 | 11 | 0.636364 | 78 | 0.0 | 55.700090 |
| 46 | ziti pasta | 0.402639 | 7 | 0.636364 | 78 | 0.0 | 55.375988 |
| 19 | italian sausages | 0.448237 | 61 | 1.090909 | 48 | 0.0 | 54.886246 |
| 24 | dried whole thyme | 0.442518 | 51 | 1.000000 | 58 | 0.0 | 54.612270 |
| 12 | italian seasoning mix | 0.471910 | 75 | 1.454545 | 16 | 0.0 | 54.226377 |
| 38 | chianti wine | 0.410693 | 23 | 0.909091 | 70 | 0.0 | 52.100864 |
| 29 | sliced mushrooms | 0.429246 | 41 | 1.000000 | 58 | 0.0 | 50.224496 |
| 20 | globe eggplants | 0.447171 | 59 | 1.181818 | 34 | 0.0 | 48.150805 |
| 26 | fresh mushrooms | 0.440132 | 47 | 1.090909 | 48 | 0.0 | 47.502632 |
| 17 | quick-cooking barley | 0.451440 | 65 | 1.454545 | 16 | 0.0 | 47.333920 |
| 22 | hunts tomato paste | 0.445030 | 55 | 1.363636 | 24 | 0.0 | 42.432299 |
| 25 | button mushroom | 0.441169 | 49 | 1.181818 | 34 | 0.0 | 42.172266 |
| 27 | lasagna noodles | 0.432072 | 45 | 1.181818 | 34 | 0.0 | 39.881073 |
| 23 | dried red pepper flakes | 0.442688 | 53 | 1.454545 | 16 | 0.0 | 39.147158 |
| 39 | thin spaghetti | 0.409562 | 21 | 1.090909 | 48 | 0.0 | 37.047267 |
| 28 | mild italian sausage | 0.430874 | 43 | 1.363636 | 24 | 0.0 | 34.820971 |
| 32 | pitted black olives | 0.418710 | 35 | 1.181818 | 34 | 0.0 | 34.503623 |
| 30 | herb seasoning mix | 0.424856 | 39 | 1.363636 | 24 | 0.0 | 32.380550 |
| 41 | hot pepper flakes | 0.405416 | 17 | 1.272727 | 30 | 0.0 | 24.382371 |
| 47 | cannellini beans | 0.401280 | 5 | 1.181818 | 34 | 0.0 | 24.300206 |
| 34 | frozen chopped spinach | 0.416980 | 31 | 1.545455 | 12 | 0.0 | 23.505319 |
| 35 | dried italian herb seasoning | 0.415891 | 29 | 1.636364 | 8 | 0.0 | 21.272047 |
| 37 | part-skim mozzarella cheese | 0.411310 | 25 | 2.090909 | 0 | 0.0 | 17.677670 |
| 40 | italian style breadcrumbs | 0.409037 | 19 | 1.909091 | 4 | 0.0 | 13.729530 |
| 42 | sweet italian sausage | 0.405204 | 15 | 1.545455 | 12 | 0.0 | 13.583078 |
| 45 | yolk-free wide egg noodles | 0.403116 | 9 | 1.909091 | 4 | 0.0 | 6.964194 |
| 48 | contadina diced tomatoes | 0.400817 | 3 | 1.636364 | 8 | 0.0 | 6.041523 |
| 49 | italian-style diced tomatoes | 0.398550 | 1 | 2.090909 | 0 | 0.0 | 0.707107 |
Notice how the "synonym" cases tend to move up to the top now?
Meanwhile while the "pairs well with" are in the lower half of the ranked list: fresh mushrooms, italian turkey sausage, cooked spaghetti, white kidney beans, etc.
df.loc[ (df["related"] >= 50) & (df["term_ratio"] > 0) ]
| ingredient | similarity | sim_pct | levenshtein | lev_pct | term_ratio | related | |
|---|---|---|---|---|---|---|---|
| 1 | dry basil | 0.618740 | 97 | 0.272727 | 98 | 1.0 | 97.501282 |
| 5 | fresh basil | 0.574703 | 89 | 0.363636 | 96 | 1.0 | 92.566193 |
| 0 | dried basil leaves | 0.677376 | 99 | 0.636364 | 78 | 1.0 | 89.120705 |
| 13 | basil | 0.470737 | 73 | 0.545455 | 90 | 1.0 | 81.942053 |
| 3 | dried sweet basil leaves | 0.593628 | 93 | 1.181818 | 34 | 1.0 | 70.017855 |
| 18 | fresh basil leaf | 0.450319 | 63 | 0.818182 | 72 | 1.0 | 67.649834 |
| 16 | fresh basil leaves | 0.451666 | 67 | 1.000000 | 58 | 1.0 | 62.661791 |
Exercises¶
Exercise 1:
Build a report for a human-in-the-loop reviewer, using the rank_related() function while iterating over vocab to make algorithmic suggestions for possible synonyms.
Exercise 2:
How would you make algorithmic suggestions for a reviewer about which ingredients could be related to a query, e.g., using the skos:broader and skos:narrower relations in the skos vocabulary to represent hypernyms and hyponyms respectively?
This could extend the KG to provide a kind of thesaurus about recipe ingredients.