Overview¶

Open Source Integration¶
The kglab package is mostly about integration. On the one hand, there are useful graph libraries, most of which don't share much common ground and can often be difficult to use together. One the other hand, there are the popular tools used for data science and data engineering, with expectation about how to repeat process, how to scale and leverage multi-cloud resources, etc.
Much of the role of kglab is to provide abstractions that make these integrations simpler, while fitting into the tools and processes that are expected by contemporary data teams in industry. The following figure shows a landscape diagram for how kglab fits into multiple technology stacks and related workflows:
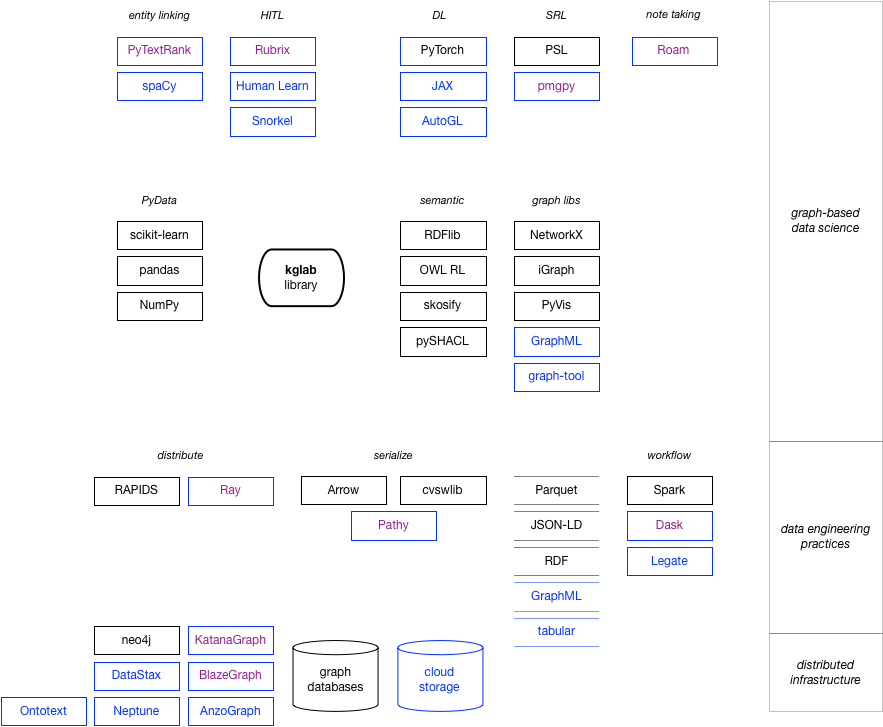
Items shown in black have been implemented, while the items shown in blue are on our roadmap. We include use cases for most of what's implemented within the tutorial.
Just Enough Math, Edition 2¶
To be candid, kglab is partly a follow-up edition of Just Enough Math – which originally had the elevator pitch:
practical uses of advanced math for business execs (who probably didn't take +3 years of calculus) to understand big data use cases through hands-on coding experience plus case studies, histories of the key innovations and their innovators, and links to primary sources
JEM started as a book which – thanks to quick thinking by editor Ann Spencer – turned into a popular video+notebook series, followed by tutorials, and then a community focused on open source. Seven years later the field of data science has changed dramatically This time around, kglab starts as an open source Python library, with a notebook-based tutorial at its core, focused on a community and their business use cases.
The scope now is about graph data science, and perhaps someday this may spin-out a book or other learning materials.
Abstraction Layer¶
The overall intent of kglab is to build an abstraction layer for KG work in Python. This is provided as a library, not as a framework. It's difficult to imagine how to implement this kind of abstraction layer outside of a functional programming language.
Consider the fact that many dependencies have their origins in the Semantic Web. The ongoing work of W3C provides ontologies, standards, and other initiatives that are incredibly valuable for graph data science. That overall effort began in the 1990s, and arguably its momentum imploded circa 2005 – despite best intentions by brilliant individuals and quite capable organizations.
In retrospect, it was a classic case of a technology being "too early" since those efforts generally lacked the necessary compute resources and language constructs. The "Big Data" efforts did not really take off until a few years following 2005. For example, Apache Spark would never have been possible prior to the mid-2000s introduction of: the Scala language (2004), commodity multi-core processors (2005), cloud computing (2006), actor model (2006), and so on.
Arguably, many challenges faced by the Semantic Web developer community can be traced to their nearly-exclusive focus on using Java, C, or C++ for reference implementions of their proposed standards. They did not benefit from so many of the learnings about distributed systems which arrived a decade later.
In particular, applicative systems leverage functional programming constructs to implement valuable uses of advanced math when working with data at scale. This allows for cost-effective parallel processing that is relatively simple to use. As a "thought exercise" consider how the semantic technologies may have differed if they'd been launched after Spark became popular? Stated differently, kglab is a direct exploration of how semantic technologies and other graph-based techniques can be improved by using contemporary distributed systems as a foundation.
Python 3.x provides just enough of a foundation as a functional programming language – e.g., classes, type annotations, closures, and so on – to make kglab feasible. While perhaps this might be simpler to write in Clojure, Scala, Haskell, etc., those languages lack enough "critical mass" in terms of graph libraries or user communities to sustain this kind of open source project.